







Du brouillon aux retours de relecture par les pairs en trois étapes
Déposez votre brouillon
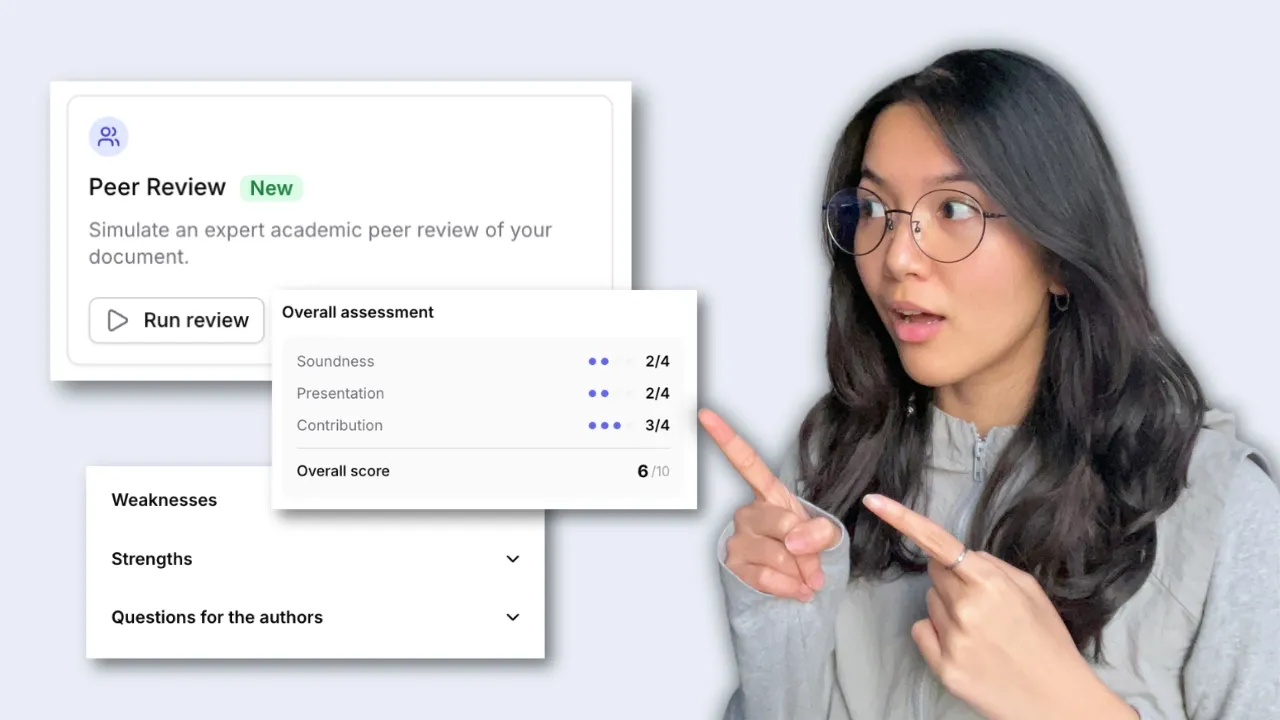
Lancer l’évaluation par les pairs
Jenni examine votre manuscrit selon les critères standards de l’évaluation par les pairs, attribue une note aux points clés et met en évidence, directement dans votre brouillon, les सुधारations concrètes à apporter.
Résoudre, relancer, recommencer
Les commentaires apparaissent directement dans votre manuscrit, associés aux passages précis qui nécessitent des améliorations. Corrigez chaque point et regardez votre score s’améliorer.
Découvrez la relecture par les pairs en action
Découvrez comment Jenni lit un véritable manuscrit, l’évalue à l’aide de la grille, et laisse des commentaires là où chaque section peut être améliorée.
Conçu pour l’exigence académique
La plupart des outils d’IA se contentent de vous donner des retours génériques sur votre rédaction. Peer Review évalue votre manuscrit comme le ferait un véritable relecteur.

Lit l’intégralité du manuscrit
Peer Review lit votre brouillon intégralement, de la première à la dernière page, en prenant en compte chaque affirmation, chaque note méthodologique et chaque transition, afin que les retours reflètent l’ensemble du document.

Les mêmes critères que les évaluateurs utilisent
Peer Review remplit le même formulaire d’évaluation que celui utilisé par les grandes revues, avec des notes sur la solidité, la contribution et la présentation, ainsi qu’un retour écrit.

Commentaires liés aux passages
Jenni relie chaque commentaire à une phrase précise, avec une explication et une suggestion de correction. Vous savez exactement quoi modifier et où, pas seulement qu’il y a un problème.
Votre examen complet des citations avant soumission
La relecture par les pairs est l’un des quatre outils de vérification qui détectent les problèmes avant même les évaluateurs. Utilisez-les ensemble pour effectuer une vérification complète avant la soumission.
Peer review8 / 10
Manuscript scored against a peer-review rubric with reviewer comments on each section.
Soundness
3/4
Presentation
4/4
Contribution
3/4
Results
Strengths
Weaknesses
Claim confidence10 issues
The claim confidence analysis addressed issues of redundant, weak, or missing citations, alongside instances of contradiction in citation arguments.
Misrepresented
Contradicted
3Unsupported
4Weakly supported
2Overstated
Unverifiable
Outdated
2Self-citation heavy
Predatory source
Citation mismatch
1Proofread18 edits
Whilst generally sound, the text contains some areas for improvement to comply with academic best practices.
Word choice
AllThe majority of participants reported improved outcomes.
Formality
Yang (2024) found a negative correlation which was interesting..
Grammar
These results indicate that early intervention be effective. appears to be effective.
Transitions
Also, In addition, Jones (2022) found similar results.
Overgeneralized
AllThe majority of participants reported improved outcomes.
The results provesuggest that X has an effect on Y.Tone of voice22 notes
Suggestions across vocabulary, syntax, punctuation, tone and flow to keep a consistent academic voice.
All Suggestions
22Vocabulary
6Syntax
5Punctuation
4Tone
3Flow
4Évaluation par les pairs
Affirmez Votre Confiance
Relisez vos documents
Ton de voix


Nos utilisateurs ont publié des articles dans plus de 100 revues
De véritables recherches, publiées dans des revues comme IEEE, Springer et Elsevier — pensées et rédigées avec Jenni.
