By
Nathan Auyeung
—
Quasi Experimental Design Examples: Types and Real Use Cases

Nathan Auyeung
Senior Accountant at EY
Graduated with a Bachelor's in Accounting, completed a Postgraduate Diploma of Accounting

Quasi-experimental designs help researchers study cause and effect when random assignment isn’t possible. Instead of relying on controlled random groups, these studies use real-world settings such as schools, clinics, neighborhoods, or regions.
That makes them especially useful in education, healthcare, and public policy, where researchers often need answers but can’t fully control who receives an intervention.
In this guide, we’ll look at the most important quasi-experimental examples, explain what makes each design work, and show how to choose and apply the right approach in your own study with clarity and confidence.
<CTA title="Design Better Research Faster" description="Generate structured quasi experimental designs with clarity and strong logic in minutes." buttonLabel="Try Jenni Free" link="https://app.jenni.ai/register" />
What Is a Quasi Experimental Research Design?
A quasi-experimental research design examines cause and effect without random assignment.
Instead of creating random groups, it uses naturally formed groups that already exist in real settings, which makes the approach more realistic for applied research. Researchers commonly work with existing classrooms, hospitals, or communities.
As explained in quasi experimental design, quasi-experiments are widely used in applied studies because they offer a practical balance between feasibility and meaningful causal insight.
Unlike a true experiment, participants are not randomly assigned to conditions. This can make it harder to rule out alternative explanations, since the groups may differ from one another before the intervention begins.
As a result, internal validity can be a challenge in quasi-experimental designs. Even with these limitations, quasi-experimental methods remain essential across disciplines such as sociology, psychology, and economics.
Independent variable: the intervention or treatment
Dependent variable: the outcome measured
Control group: the comparison group that does not receive the treatment
Treatment group: the group that receives the intervention
<ProTip title="💡 Pro Tip:" description="Always define variables clearly before selecting a quasi experimental design." />
Core Types of Quasi Experimental Design Examples
Here are the main types you'll see in practice. The explanations include simple examples and where you'd actually use them.
Nonequivalent control group design
Two groups are compared, but they weren't randomly assigned. They already existed.
Example: One class at a school gets a new math program. Another class uses the old method. At the end of the term, you compare their test scores.
Where it's used: This is everywhere in education research. Since the groups weren't created equal to start, researchers have to use statistics (like ANCOVA) to try and account for the initial differences. The big challenge is dealing with variables you didn't account for.
One-group pretest-posttest design
You measure a single group, introduce something, then measure them again. There's no separate control group.
Example: A factory records how many accidents happen over six months. Then they run a safety training program. Afterward, they track accidents for another six months to see if the number went down.
Why it's weak: The drop in accidents might be because of the training. Or it might be because of something else that happened at the same time, like a seasonal slowdown in production. It's hard to be sure what caused the change.
The trade-off: It's very easy and cheap to do, which is why it's common in business and workplace studies. But it gives you the weakest evidence for cause and effect.
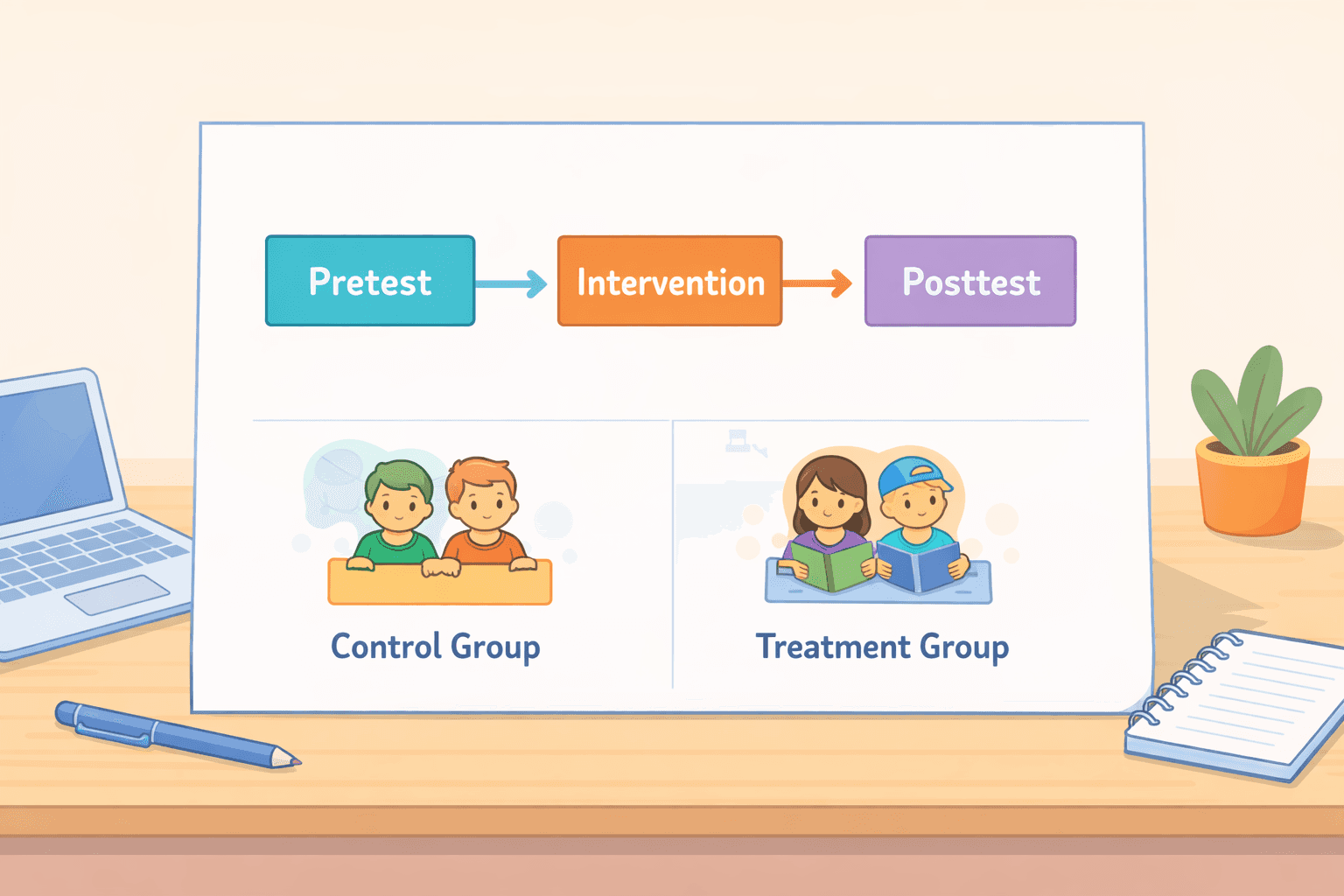
Pretest-posttest with a nonequivalent control group
This is a stronger version. You have two existing groups, and you measure both of them before and after you introduce a change to just one group.
Example: A clinic starts a new program to help people quit smoking. Another similar clinic doesn't. You survey smokers at both clinics about their habits. After a year of running the program at the first clinic, you survey everyone again.
Why it's better: If the clinic with the program shows a much bigger drop in smoking than the other clinic, you can be more confident the program actually worked. It helps rule out the possibility that some outside factor (like a new public health campaign) affected everyone at the same time.
Here’s how these first three designs stack up:
Design Type | Control Group? | Pretest? | Strength of Evidence |
One-group pretest-posttest | No | Yes | Low |
Nonequivalent control group | Yes | Optional | Medium |
Pretest-posttest with control | Yes | Yes | Higher |
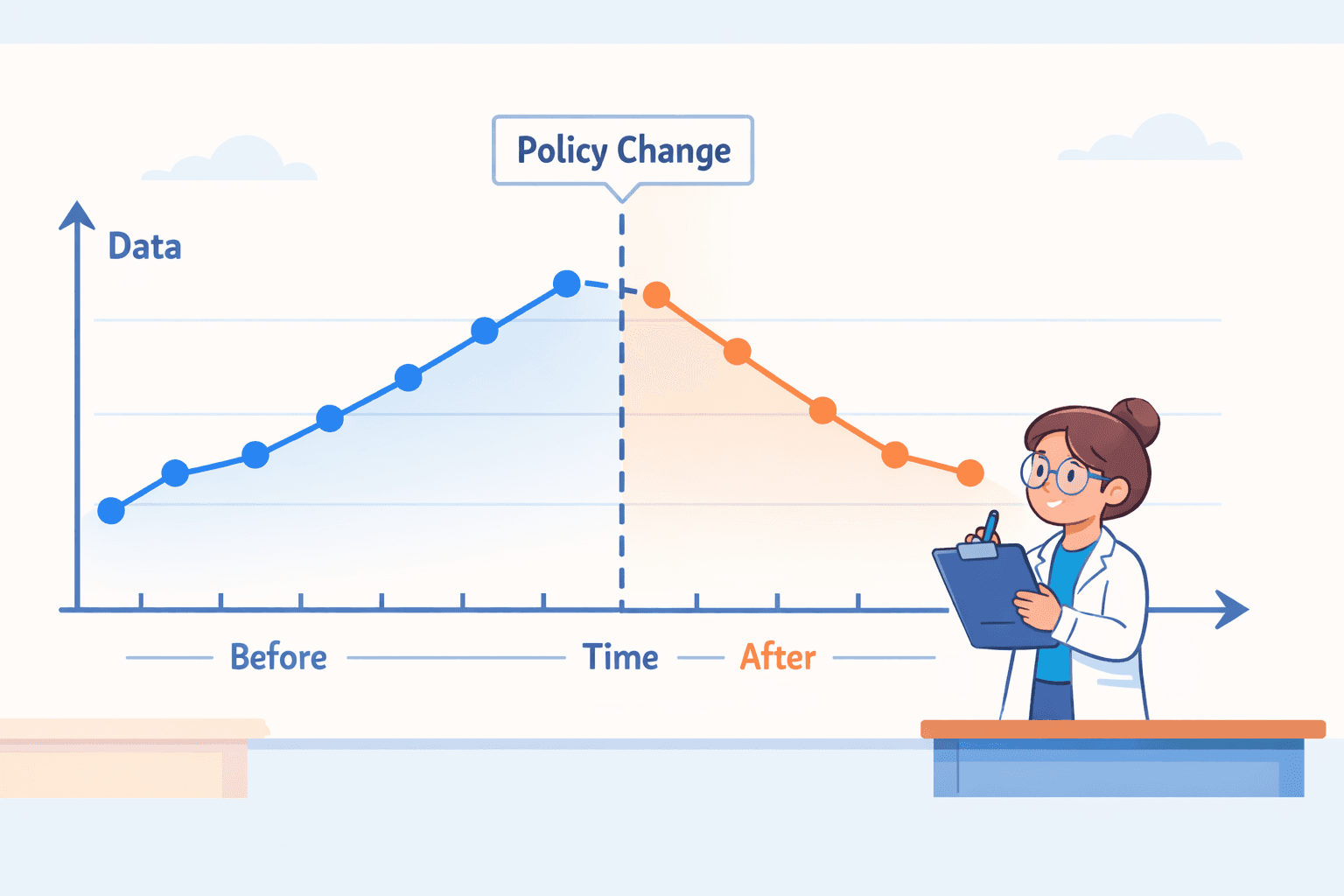
Interrupted time series design
Instead of just one "before" and one "after" measurement, you collect data at many points over a long period. You look for a shift in the trend after a specific event.
Example: A country passes a law adding a tax to sugary drinks. Researchers analyze nationwide soda sales data month-by-month for years before the tax and years after. They're looking to see if the long-term trend of sales clearly drops or changes shape right when the tax started.
Why it's useful: Why it's useful: It's powerful for evaluating policies and laws. Seeing a change in a long-term pattern is more convincing than a change between two single points in time. A detailed applied discussion can be found in interrupted time series design in real world studies, which shows how time-based designs are used in real-world health research.
<ProTip title="📊 Reminder:" description="Use at least 12 time points before and after for strong ITS analysis." />
Regression discontinuity design
People are assigned to a treatment group based on whether they fall above or below a specific cutoff point on a scale.
Example: A university gives tutoring grants to students whose family income is below $50,000. Researchers then compare the graduation rates of students who just barely qualified (e.g., income of $49,500) with those who just barely missed it (e.g., income of $50,500).
The logic: The idea is that these two groups of students are virtually identical in every way except for that tiny income difference and the grant they received. Any big difference in their outcomes can be more safely linked to the grant. Economists and policy analysts love this design for its clever logic.
Matching and propensity score designs
Since you can't randomize, you try to fake it with statistics. You find individuals in the treatment group and "match" them with nearly identical individuals from a non-treatment group.
Example: You're studying online versus in-person college courses. You take each online student and find an in-person student with the same high school GPA, age, and major. Then you compare the grades of these matched pairs.
The catch: You can only match people based on things you can measure and have data for. It can't account for hidden differences, like one student's level of motivation or their access to a quiet place to study. It reduces bias, but doesn't eliminate it.
<ProTip title="⚙️ Pro Tip:" description="Always check balance after matching to validate your quasi experimental design." />
Real-World Quasi Experimental Design Examples by Domain
You see these methods all over the place. Here’s how they look in practice across a few major areas.
Education
Schools can't usually shuffle kids around randomly for an experiment. So they work with the groups they have.
What it looks like: A school district decides to try a new online tutoring program. They give it to all the students at Lincoln High School. Meanwhile, the students at Jefferson High School keep using the old study hall system. At the end of the semester, researchers compare the final exam scores from both schools.
Why it's used: It's a standard, practical way to test new teaching tools or programs when true randomization isn't an option.
Healthcare
Hospitals and clinics use existing patient groups to study new procedures or systems.
What it looks like: A hospital installs a new digital system for nurses to track patient vital signs. They look at the average recovery time for patients admitted in the six months before the system went live, and compare it to the recovery time for patients in the six months after.
Why it's used: You can't randomly assign some patients to get worse care. This approach lets healthcare researchers study real-world improvements in a controlled way.
Public Policy
When a new law or tax is introduced, it affects everyone. Researchers study the effects by looking at data over time.
What it looks like: A state raises the legal age to buy tobacco from 18 to 21. Public health officials then track statewide smoking rates among teenagers for several years before and after the law changed, looking for a drop in the trend line.
Why it's used: This is often an interrupted time series design. It's the main way to figure out if a large-scale policy actually caused the change everyone hoped for.
Business and Marketing
Companies test new ideas on a subset of customers before a full launch, often because a true A/B test isn't possible.
What it looks like: A social media app develops a new video feature. They release it first to all users in Canada. For three months, they track how often Canadian users watch videos compared to users in similar markets, like the UK and Australia, who don't have the feature yet.
Why it's used: Analysts, even in forums like Reddit, call this a "staggered rollout." It lets a company see real-world usage and spot problems before a global launch, while still gathering comparative data.
This type of study often sits between qualitative insight and quantitative measurement. If you're unsure how these approaches differ, qualitative vs quantitative research explains how each method contributes to research design decisions.
Advantages and Disadvantages of Quasi Experimental Design
Knowing what these methods are good at, and where they fall short, is key to judging the studies that use them.
Advantages
The biggest strength is that they let you study things when a true experiment isn't possible or ethical.
Real-world use: You can research programs, policies, and treatments as they actually happen in schools, hospitals, or cities. You aren't creating an artificial lab setting.
Ethical practicality: Often, you can't randomly deny someone a potentially helpful treatment. The National Institutes of Health points out that many clinical studies have to use non-randomized designs for exactly this reason.
Efficiency: Researchers can frequently use data that already exists, like school records or hospital admission logs. This makes studies faster and less expensive to run.
Scale: These designs can be applied to large groups, even entire populations, which is necessary for evaluating things like new laws or public health campaigns.
Disadvantages
The major trade-off is a weaker claim about cause and effect. You can't be as sure that the treatment you're studying is the real reason for any change.
The core problem: Without random assignment, the groups you're comparing might have been different from the start. Maybe the students in the new math program had more supportive parents. Maybe the patients who received a new therapy were generally healthier. These pre-existing differences can skew your results.
Confounding variables: These are the unmeasured factors that might actually be responsible for the outcome. They're the constant threat in this type of research.
Selection bias: The way people end up in one group or another isn't random. People who choose to join a new program might be more motivated than those who don't, which itself could lead to better results.
Uncertainty: At the end of the day, you're left with a strong correlation, similar to what you see in correlational research, but not definitive proof of causation. The evidence is suggestive, not bulletproof.
A deeper explanation of these challenges and how researchers handle them is discussed in quasi experimental design validity and causal inference, which explores causal inference and validity issues in quasi-experimental designs.
<ProTip title="⚠️ Note:" description="Always report limitations clearly to strengthen research credibility." />
How to Design a Quasi Experimental Study Step by Step
If you need to run one of these studies, here’s a straightforward path to follow.
1. Define your question Start with a clear cause-and-effect question. Be specific.
Weak: "Does the program work?"
Better: "Do high school students who complete the new peer-tutoring program show a greater increase in algebra final exam scores than those who do not?"
2. Find your groups You won't be creating groups randomly. You'll use ones that already exist.
Treatment group: The people, classrooms, or regions that will receive the intervention (e.g., the three company branches getting new software).
Control/comparison group: The groups that will continue as usual (e.g., the two branches that keep the old system). Your goal is to make these groups as similar as possible from the start.
3. Pick your design Your choice depends entirely on what's practical for your situation.
If you only have access to one group, you'd use a one-group pretest-posttest design.
If you have two existing groups and can measure them before and after, use a pretest-posttest with a nonequivalent control group.
If you're studying a policy change and have data over many years, an interrupted time series design is your best bet.
If treatment is decided by a strict cutoff (like a test score or income level), a regression discontinuity design is the most rigorous option.
4. Account for other variables This is the most critical analytical step. Since you didn't randomize, you must try to control for other factors statistically, and use measures that are as reliable as possible.
Matching: Pair each person in the treatment group with someone in the control group who has similar characteristics (age, prior test score, etc.).
Regression analysis: Use this to isolate the effect of your treatment while mathematically holding other variables constant.
Difference-in-differences: Compare the change in the treatment group to the change in the control group. This helps cancel out trends that affected both groups.
If you're still deciding how these methods fit into your broader research approach, research paradigms can help clarify how different designs align with research goals.
5. Analyze and report with caution Interpret your numbers carefully.
Don't claim you "proved" the intervention caused the change. Say the evidence "suggests" or "supports" a causal link.
Be upfront about the study's limitations. Explicitly list the other variables you couldn't control for that might have influenced the results. This honesty is what makes the research credible.
When reporting findings, clarity in citation style also matters for credibility. If you're formatting academic writing, et-al example apa provides guidance on proper citation usage in research papers.
<ProTip title="🧠 Pro Tip:" description="Use difference in differences to control time trends in quasi experiments." />
Final Thoughts on Quasi Experimental Design
You’ve probably felt how tricky it is to prove cause and effect when you can’t control everything, and results can feel uncertain or easy to question. It’s frustrating. These designs help you work with real conditions while still getting useful answers, even when perfect setups aren’t possible.
<CTA title="Turn Your Research Idea Into a Clear Design" description="Plan and structure quasi experimental studies with clarity and confidence using guided AI support." buttonLabel="Try Jenni Free" link="https://app.jenni.ai/register" />
Instead of overthinking every limitation, focus on building a clear structure and explaining your choices well. Tools like Jenni can help you organize your ideas faster and keep your writing sharp, so you spend less time stuck and more time moving your research forward.