

AIが間違いを犯したとき、それは通常「ハルシネーション(幻覚)」と呼ばれます。人間が嘘を広めるとき、それは「誤情報(ミスインフォメーション)」です。どちらも間違った事実を伝えますが、その発生源は全く異なります。
自分がどちらを扱っているのかを知ることは、特に仕事や研究でAIツールをサポートとして使っている場合、非常に重要です。
それぞれの問題の始まり方や広がり方は異なります。これは、何が間違っていたのかを突き止め、どのように修正するか、あるいは少なくとも次回どのように防ぐかを見極めるために重要です。
<CTA title="AI出力の正確性を向上させる" description="構造化されたプロンプトを作成し、明確さとコントロールを持ってAIの出力を検証します。" buttonLabel="Jenniを無料で試す" link="https://app.jenni.ai/register" />
AIハルシネーションと誤情報の違いとは?
これら2つの概念は混同されがちです。どちらも最終的に間違った情報を得ることになりますが、そこにたどり着くまでの経路は全く別物です。
AIハルシネーションとは?
システムの一時的な不具合と考えてください。AIが自信満々に嘘を吐き出すとき、それをハルシネーションと呼びます。これは、トレーニングの欠陥や、単純な予測プロセスのエラーによって発生します。これらのモデルは、シーケンス内で次に来る最も確率の高い単語を推測することによって動作します。
彼らは真実を探しているのではなく、それらしく聞こえるテキストを組み立てているのです。このため、厳密な境界線を設定することで、執筆時におけるAIハルシネーションを減らす方法を学ぶことが極めて重要になります。
スタンフォード大学の人間中心AI研究所は、2023年の報告書の中で、AIが十分に理解していないトピックについて尋ねられた際、これらの捏造がより起こりやすくなると指摘しています。
誤情報とは?
これは人間から始まります。誤情報とは、人々によって共有される、虚偽または誤解を招く情報のことです。ここでの鍵は意図であり、通常はそれを信じている人、あるいは少なくとも害を及ぼすつもりのない人によって共有されます。
オンラインにおける真実と虚偽のニュースの拡散を理解すると、誤情報は批判的なチェックよりも信頼が優先されるソーシャルネットワークを通じて拡散することが多いことがわかります。
それは素直な間違い、偏見、あるいは単に全貌を把握していないことによって広がります。最新の治療法だと思い込んで、健康に関する古い記事を共有するのは典型的な例です。
WHOなどの組織は、この用語を、意図的に悪意があるわけではない不正確な情報を指す言葉として特別に使用しています。
なぜ誰もが混同してしまうのか?
結果は同じです:間違った事実が手元に残ります。しかし、そのメカニズムは異なります。ハルシネーションはマシンのエラーです。誤情報は人間の行動です。
この境界線が曖昧になるのは、AIのハルシネーションによる出力が人間に拾われ、オンラインで共有されたときです。突然、技術的な欠陥が社会的な問題へと姿を変えるのです。
<22"><ProTip title="💡 プロのヒント:" description="信頼できる情報源で検証されるまでは、AIの出力は事実ではなくドラフト(下書き)として扱ってください。" />
AIハルシネーションと誤情報の主な違い
主な違いは、それがどこで始まり、どのように移動するかにあります。
直接的な比較
側面 | AIハルシネーション | 誤情報 |
起源 | AIのプログラミングまたはデータの欠陥。 | 人間が抱く間違いや思い込み。 |
意図 | 存在しない。偶発的なもの。 | 通常はない、あるいは少なくとも悪意のあるものではない。 |
メカニズム | AIが次に来るべき単語を予測する。 | 人々が虚偽の何かを共有し、議論し、または信じる。 |
例 | AIが歴史的事実を捏造する。 | 誰かが時代遅れの財務アドバイスをネット上に投稿する。 |
見極め方 | AIが完全に自信たっぷりに提示するため、困難である。 | トピックによる。明らかな場合もあれば、そうでない場合もある。 |
実際の機能の仕方
AIハルシネーションは、非常にスマートで、かつ大きく壊れた自動補完機能のようなものです。システムに知識のギャップがあり、それを認める代わりに、そのスペースを埋めるためにそれらしい何かを作り上げます。
誤情報は人々を介して伝わります。感情、恐怖、興奮、すでに考えていることを裏付けたいという欲求、そして単に十分に繰り返されることで真実らしく聞こえ始めることによって促進されます。
単純な例えを挙げましょう。バグのせいでAIハルシネーションが「2 + 2 = 5」という電卓の計算結果を出すことだとすれば、誤情報は、友人が間違って覚えたために答えは5だと教えてくれるようなものです。
これらが組み合わさるとき
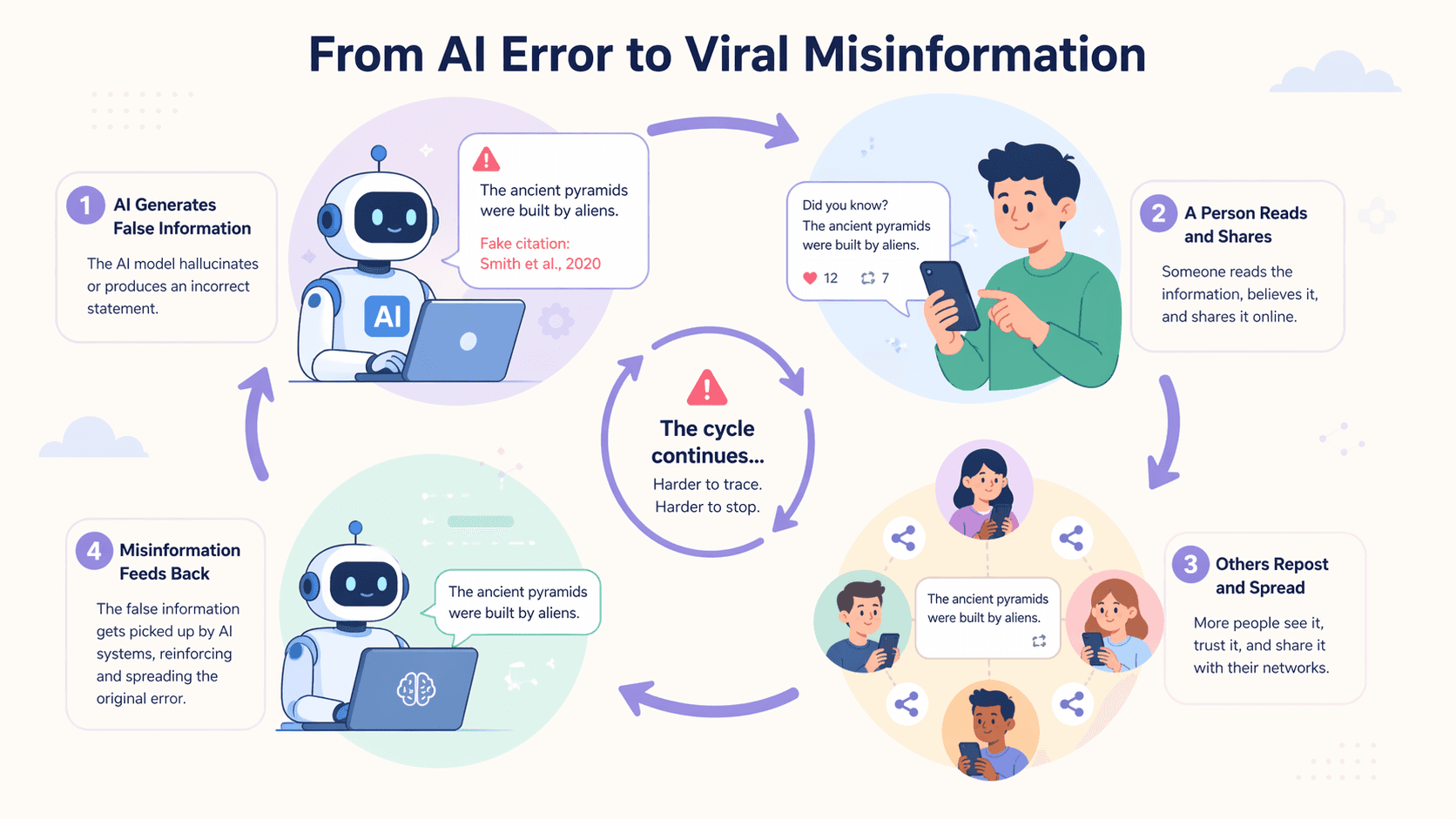
ここからが厄介なところです。AIが間違った統計をハルシネーションし、それを人間が共有することがあります。これにより、最初の虚偽の出所を追跡することがより困難になるサイクルが生まれます。
大規模言語モデルの内部一貫性に関する研究は、これらのモデルが一般の読者にとって完全に本物に見える欺瞞的なコンテンツをどのように生成し得るかを探求しているため、ここで役立ちます。
他の人々がそれを見て信頼し、もしかしたら別のAIシステムにフィードバックするかもしれません。このループにより、最初の偽事実の追跡はさらに難しくなり、根絶することは困難になります。
<ProTip title="📌 注意:" description="AIハルシネーションは、人間が検証せずに共有した時点で誤情報になります。" />
AIハルシネーションの原因とは?
主な理由は、AI言語モデルが「真実を語る」ために作られていないことです。それらは「心地よく響く文章を書く」ために作られています。これがいくつかの特定の技術的問題につながります。
知っているのではなく、推測して動いている
これらのモデルは確率に基づいて動作します。事実を確認するのではなく、トレーニングデータ内のパターンに基づいて次の単語を予測します。もっともらしく聞こえる言葉の連なりが、仮に虚偽であっても、AIはそれを生成してしまいます。
AIは正確な情報ではなく、一貫した言語として最適化されています。曖昧なことや極めて新しいことについて質問すると、その予測の信頼性は低くなります。
MITテクノロジーレビューの記事は、ニッチな質問がこれらの捏造を引き起こす一般的なトリガーであると指摘しています。
トレーニング素材に穴がある
これらのAIが学習するデータは膨大ですが、欠陥もあります。不完全であったり、古かったり、矛盾する記述で満ちていたりすることがあります。モデルが特定の出来事や概念について十分な情報でトレーニングされていなかった場合、知識のギャップが生じます。
リクエストを完了するために、AIは即興で関連するトピックのパターンをつなぎ合わせ、もっともらしいが捏造された回答を作成します。
質問の意図を誤解することがある
これは「セマンティック・ドリフト(意味の漂流)」と呼ばれます。AIはプロンプト内の1つの単語にとらわれて暴走し、実際の質問を見失うことがあります。
これにより、間違った前提に基づいた回答、完全に的外れな回答、あるいは無関係なアイデアの間に捏造された関連性を作り出す回答が導き出されます。
研究用のソフトウェアを選択する際、誠実さを維持するためには、クリエイティブな「推測」よりも事実に基づいたグラウンディングを優先するAI執筆ツールの選び方を知ることが不可欠です。
ハルシネーションが最も起こりやすいのはいつか?
特定の条件下では、それらがより頻繁に発生します:
質問が曖昧であるか、複数の解釈ができる場合。
トピックが非常に新しいか専門的すぎて、AIのデータが不足している場合。
「Xに関することすべて」のように、非常に大雑把な質問をした場合。
具体的な数字、情報源、引用を特に要求した場合、AIはプロンプトを満たすためにそれらを捏造することがよくあります。
<ProTip title="💡 プロのヒント:" description="AIの回答におけるハルシネーションのリスクを減らすために、具体的かつ限定的な質問をしてください。" />
AI時代における誤情報の拡散方法
今日、虚偽情報が移動する方法は変化しています。AIツールは火をつけはしませんが、そこにガソリンを注ぐことはできます。
人間がエンジンである
誤情報が広まるのは、私たちがそれを信じるからです。私たちは友人を信頼し、自分の意見に合うストーリーを好み、自分を怒らせたり期待させたりするものを共有します。ソーシャルメディアのプラットフォームは、こうした人間の自然な行動を取り込み、そのスピードを加速させます。
世界経済フォーラムは、この「人間のバイアス」と「デジタル規模」の複合的な脅威を、重大な世界的リスクとして位置づけています。
AIがどのように問題を煽るか
AIシステムは、たった一つの虚偽情報を乗算することができます。これらはいくつかの方法で行われます:
欠陥のあるアイデアに基づいて、何千もの記事、投稿、またはコメントを作成できる。
自信に満ちた専門家のようなトーンで書くため、コンテンツの信頼性が高く見える。
トレーニングデータにすでに誤情報が含まれていた場合、それを繰り返して強化してしまう可能性がある。
これは、言語モデルによる数学的発見に関する新たなリスクへとつながります。ドメイン専門家によって適切に検証されない場合、高度な自動化システムであっても系統的なエラーを伝播させる可能性があります。
嘘の新しいライフサイクル
現在、以下のようなパターンが一般的になっています:
AIモデルが、おそらくハルシネーションを通じて、誤った記述を生成する。
人間がそれを読み、プロっぽく見えるという理由で真実だと思い込み、ネット上に投稿する。
他の人がそれを見て、共有した人を信頼し、自らもリポストする。
そのアイデアが勢いを得て、周知の事実のように感じられ始める。
このループは、単に元の誤った事実を拡散するだけではありません。信頼を直接損なうAIシステム自体への不信感も生み出します。情報源を手動でチェックすることが、かつてないほど重要になっています。
リスクと現実世界への影響
AIの不具合と人間の嘘の違いを知ることは、単なる学術的な話ではありません。間違いが深刻な結果をもたらす場所において重要になります。
研究と科学の分野において
ハルシネーションは、捏造されたデータやフェイクの情報源につながる可能性があります。これを避けるために、すべての研究者は、引用されたすべての参考文献が現実世界に実際に存在することを確認するために文献管理ツールを使用すべきです。
論文執筆を支援するためにAIを使用することは、ひどい裏目に出る可能性があります。ツールがハルシネーションを起こすと、架空の論文をでっち上げたり、データを捏造したり、存在しない情報源を引用したりすることがあります。
この虚偽の情報を含めてしまった研究者は、投稿が却下される、あるいは最悪の場合、出版された論文を後に撤回せざるを得なくなる事態に直面する可能性があります。
彼らの評判は直接的な打撃を受けます。学術界で働いているのであれば、手法の透明性を保つために、学術執筆においてAIの使用を明確に開示する方法を知っておくことも価値があります。
AIが生成した偽の参考文献が、査読に送られた草稿に紛れ込んでしまった事例は、すでに文書で記録されています。
法律と医療の分野において
ここではさらにリスクが高くなります。判例や法令をハルシネーションしたAIを使用している弁護士は、現実に基づかない土台の上に弁護を組み立ててしまう可能性があります。
医療において、診断サポートをAIに頼っている医師や看護師は、確信を持って提示されるものの完全に間違った提案を受け取ってしまうかもしれません。
これらのシナリオは仮定の話ではありません。これらの分野におけるAIのすべての出力を、人間が検証済みの情報源と照らし合わせて確認しなければならないと専門家が強調する理由がここにあります。
崩れゆく信頼
AIが生成したコンテンツに間違いが何度も見つかると、人々はそれを信頼しなくなります。これは特定の1つのボットだけの問題ではありません。
学術界や専門家の間での広範な懸念は、隠れた不正確さを含むAI支援の仕事が氾濫することで、出版された研究結果、法的文書、そして医療のアドバイスに対する一般の信頼が全面的に損なわれかねないということです。
進歩を助けるはずのツールが、代わりに私たちにすべてを疑わせることになるかもしれません。
<ProTip title="⚠️ 注意:" description="リスクの高い分野では、AIが生成したすべての主張に対して人間による検証が必要です。" />
AIハルシネーションと誤情報の検出方法
AIが発した情報をチェックするための実践的な方法をいくつか紹介します。
簡単な確認方法 AIの回答を信頼する前に、以下のポイントを確認してください:
情報源や引用はありますか?それらを確認してください。
すでに信頼しているWebサイトやデータベースを使用して、事実を確認できますか?
文章が自信に満ちすぎていて、意見を絶対的な事実として述べているように聞こえませんか?
他のいくつかの場所を見て、同じことが言われているか確認しましたか?
AIの「ハルシネーション」はどのように見えるか AIが情報を捏造している場合、以下のような点に気づくかもしれません:
架空の論文やでっち上げのニュース記事など、存在しない参考文献。
注意深く読むと、変化したり辻褄が合わなくなったりする詳細な内容。
非常に滑らかでプロフェッショナルに聞こえるが、よく考えると曖昧で中身のない説明。
たとえば、実在する研究者の論文を引用しているものの、その特定の論文は実際には出版されていない、といったケースです。
誤情報はどのように見えるか 誤解を招くように設計されたコンテンツには、多くの場合、次のような特徴があります:
説得するために、強い感情(怒り、恐れ、興奮)を呼び起こそうとする言葉遣い。
信頼でき、検証可能な情報源へのリンクが完全に欠落していること。
同じ主張が繰り返し現れるが、質の低い情報で知られるブログやSNSアカウントでのみ見られること。
それぞれの問題の見分け方の比較
注目すべき点 | AIハルシネーション | 誤情報 |
ファクトチェック | 行う必要があります。 | 行う必要があります。 |
情報源の確認 | これが最も重要なステップです。 | これが最も重要なステップです。 |
トーンの分析 | あまり役に立ちません。トーンは完全に正常に聞こえることがあります。 | より有用です。多くの場合、トーンが大きな手がかりになります。 |
クロスリファレンス(相互参照) | 非常によく機能します。 | 非常によく機能します。 |
要するに、両方を検証する必要があります。しかし、AIのハルシネーションを見破るには、奇妙な技術的詳細や、情報自体の一貫性のなさに細心の注意を払う必要があります。
AIハルシネーションを防止し、軽減する方法

AIの回答の信頼性を高めるために、具体的な対策を講じることができます。さらに詳細な戦術については、執筆におけるAIハルシネーションを減らすための効果的な実用的手法をご覧ください。
より良いプロンプトを書く 質問の仕方は重要です。明確で具体的な指示を与えることで、AIが物事をでっち上げる余地を減らすことができます。
非推奨の質問例: 「気候変動について教えてください。」
推奨の質問例: 「2020年以降に発表された気候変動に関する査読済み論文3本から、主な結論を要約してください。」
外部データアクセスを持つシステムを使用する 一部のAIツールは、ライブデータベースや情報源に接続されています。この手法は検索拡張生成(RAG)と呼ばれ、AIの回答を実際のドキュメントや事実に結びつけることで役立ちます。これは、正確性を重視して設計された新しいシステムの一般的な機能です。
人間が主体となってコントロールする 最大のチェック機能は人間です。AIの回答をただコピー&ペーストするのではなく、人間が成果物を確認するプロセスを構築してください。
手堅いワークフローは以下のようになります:
AIに最初のドラフト(下書き)を作成させます。
そのドラフト内のすべての主張を、信頼できる情報源と照らし合わせて確認します。
自分自身でテキストを編集し、仕上げます。
いくつかの実用的なルール
事実確認を行うために、信頼できる情報源(広く知られたジャーナルや公式データセットなど)を常に用意しておきます。
非常に専門的、あるいはニッチな情報については特に慎重になってください。こうした領域ではAIが間違いを犯しやすくなります。
調査の際、後から辿れるように、どこから情報を得たかを書き留めておきます。
批判的な目を持って、最終的な出力を読んでください。何かがおかしいと感じたら、おそらく本当におかしいです。
<ProTip title="💡 プロのヒント:" description="AIによる支援と手動での検証を組み合わせて、スピードと正確性のバランスを取ります。" />
代償を払う前に違いを知る
間違った情報が現れ、一見するとすべてが説得力があるように見えるとき、物事を混同してしまいがちです。何が本物なのか、自信が持てなくなってしまいます。その混乱がリスクを増大させます。
<CTA title="正確なAI支援コンテンツを作成する" description="ガイド付きのAI執筆サポートを活用して、信頼性の高いコンテンツを構築し、エラーを減らします。" buttonLabel="Jenniを無料で試す" link="https://app.jenni.ai/register" />
賢い行動は、エラーがどこから来ているかを把握し、明確なプロセスで検証することです。Jenniのようなツールは、作業内容をレビューする間、整理整頓を維持する手助けをします。思慮深い考察に完全に取って代わることはできませんが、コンテンツの正確性と信頼性を維持するための安定した方法を提供してくれます。