







Dalla bozza al feedback della revisione paritaria in tre passaggi
Inserisci la tua bozza
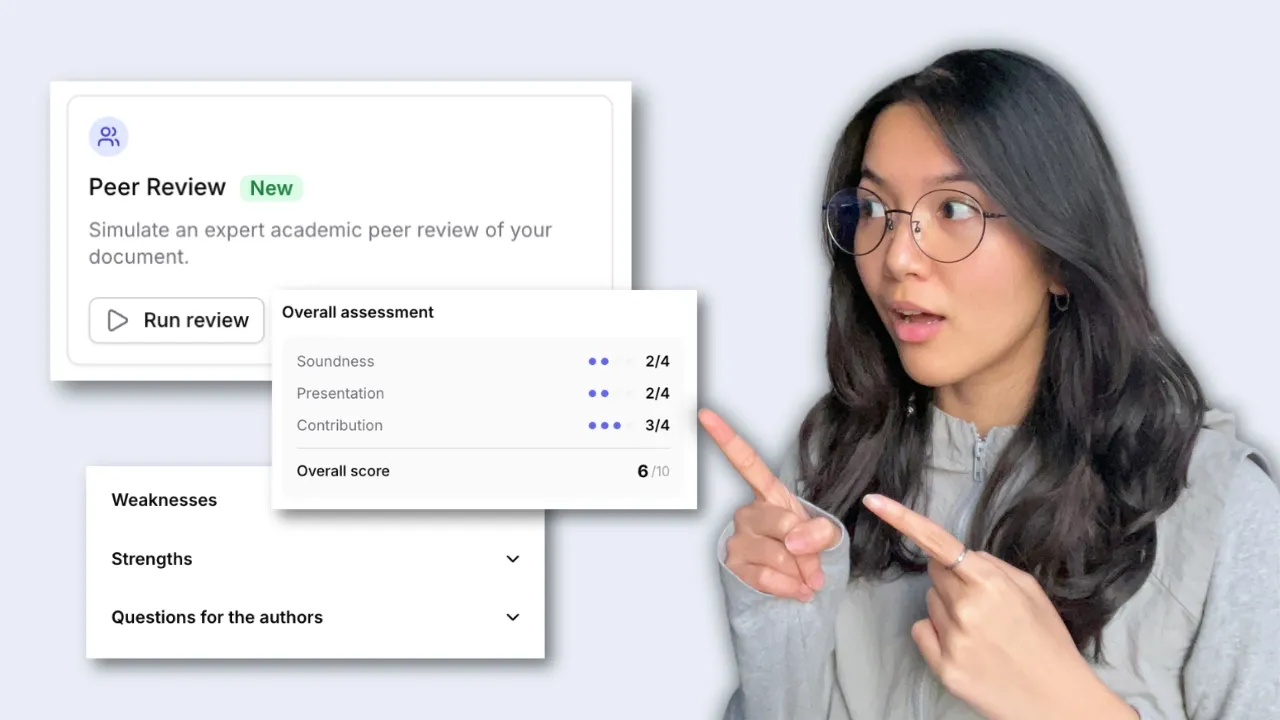
Avvia la revisione tra pari
Jenni esamina il tuo manoscritto in base ai criteri standard della peer review, assegna un punteggio alle aree chiave e segnala miglioramenti concreti direttamente nella tua bozza.
Risolvi, riesegui, ripeti
I commenti vengono inseriti direttamente nel tuo manoscritto, collegati ai passaggi esatti che richiedono interventi. Affronta ogni problema e osserva migliorare il tuo punteggio.
Scopri la peer review in azione
Guarda come Jenni legge un vero manoscritto, lo valuta in base alla rubrica e lascia commenti nei punti in cui ciascuna sezione necessita di miglioramenti.
Progettato per il rigore accademico
La maggior parte degli strumenti di IA offre un feedback generico sulla scrittura. Peer Review valuta il tuo manoscritto come farebbe un revisore.

Legge l’intero manoscritto
La peer review legge la tua bozza completa dalla prima all’ultima pagina, cogliendo ogni affermazione, ogni nota metodologica e ogni transizione, così che il feedback rispecchi l’intero documento.

Gli stessi criteri usati dai revisori
La peer review compila lo stesso modulo di revisione utilizzato dalle principali riviste, con punteggi relativi alla solidità, al contributo e alla presentazione, oltre a un feedback scritto.

Commenti associati ai passaggi
Jenni collega ogni commento a una frase specifica, con una motivazione e una correzione suggerita. Sai esattamente cosa modificare e dove, non solo che c’è qualcosa che non va.
La tua revisione completa delle citazioni prima dell'invio
La revisione tra pari è uno dei quattro strumenti di revisione che individuano i problemi prima dei revisori. Eseguili insieme per un controllo completo prima dell’invio.
Peer review8 / 10
Manuscript scored against a peer-review rubric with reviewer comments on each section.
Soundness
3/4
Presentation
4/4
Contribution
3/4
Results
Strengths
Weaknesses
Claim confidence10 issues
The claim confidence analysis addressed issues of redundant, weak, or missing citations, alongside instances of contradiction in citation arguments.
Misrepresented
Contradicted
3Unsupported
4Weakly supported
2Overstated
Unverifiable
Outdated
2Self-citation heavy
Predatory source
Citation mismatch
1Proofread18 edits
Whilst generally sound, the text contains some areas for improvement to comply with academic best practices.
Word choice
AllThe majority of participants reported improved outcomes.
Formality
Yang (2024) found a negative correlation which was interesting..
Grammar
These results indicate that early intervention be effective. appears to be effective.
Transitions
Also, In addition, Jones (2022) found similar results.
Overgeneralized
AllThe majority of participants reported improved outcomes.
The results provesuggest that X has an effect on Y.Tone of voice22 notes
Suggestions across vocabulary, syntax, punctuation, tone and flow to keep a consistent academic voice.
All Suggestions
22Vocabulary
6Syntax
5Punctuation
4Tone
3Flow
4Revisione paritaria
Affermare Fiducia
Correzione di bozze
Tono di voce


I nostri utenti hanno pubblicato articoli in oltre 100 riviste scientifiche
Ricerche autentiche, pubblicate in riviste come IEEE, Springer ed Elsevier — pianificate e redatte con Jenni.
