

只有當研究結果切實衡量了研究人員所宣稱的內容時,它們才具有價值。如果缺乏這種效度(validity),研究的結論可能會產生誤導,甚至完全錯誤。
本指南將結合心理學和臨床試驗中的清晰實例,解釋您會遇到的核心效度類型,如內部效度、外部效度和建構效度。
我們將展示如何識別它們,以及為甚麼它們對您的研究工作至關重要。準備好讓您的研究更加嚴謹了嗎?讓我們開始吧。
<CTA title="奠定更穩固的研究基礎" description="使用 Jenni 來規劃您的研究焦點、完善您的研究方向,並讓寫作更具條理。" buttonLabel="免費試用 Jenni" link="https://app.jenni.ai/register" />
理解研究中的效度類型
研究效度並不是一個單一的分數,而是整項研究的基石。如果您的方法無法衡量您所針對的概念,那麼您的研究發現就如同建立在沙灘上。
美國心理學會(American Psychological Association)將其視為心理學及相關領域中,可信工作必須遵守的強制性標準。若沒有這個基礎,即使是再複雜的統計數據也會失去意義。
研究人員將效度進行分類,以檢驗研究準確性的不同方面。每種效度都有其特定職責,有助於檢查您的測量工具是否優良,以及您的結果在現實生活中是否仍然有效。
關鍵在於將它們視為一個相互關聯的系統,而非僅僅是一份待辦清單。
如果您想更好地理解研究方法如何影響效度決策,可以探索研究正規(research paradigms),它解釋了不同研究設計背後的哲學基礎。
為甚麼這如此重要?效度會影響您做出的每一個選擇,從如何設計調查問題,到如何解讀最終數據。
它決定了您的結論是否值得信賴,以及是否能應用於特定樣本之外。
在實踐中,強大的效度能最大限度地減少偏差,從而提出更具說服力的科學論斷,這對於讓您的研究通過同行評審至關重要。這正是「初步發現」與「既定事實」之間的區別。
<ProTip title="💡 專家貼士:" description="在分析數據之前,先規劃好您的研究所需滿足的效度類型。" />
測量效度類型
測量效度關係到您的工具。它探討的是:您的調查、測試或儀器是否切實捕捉到了您正在研究的概念?如果您的溫度計量度的是樂觀情緒而非溫度,您的數據將毫無用處。
在設計研究時,特別是在比較諸如質性與量化研究中討論的方法時,您的測量選擇會直接影響效度的結果。
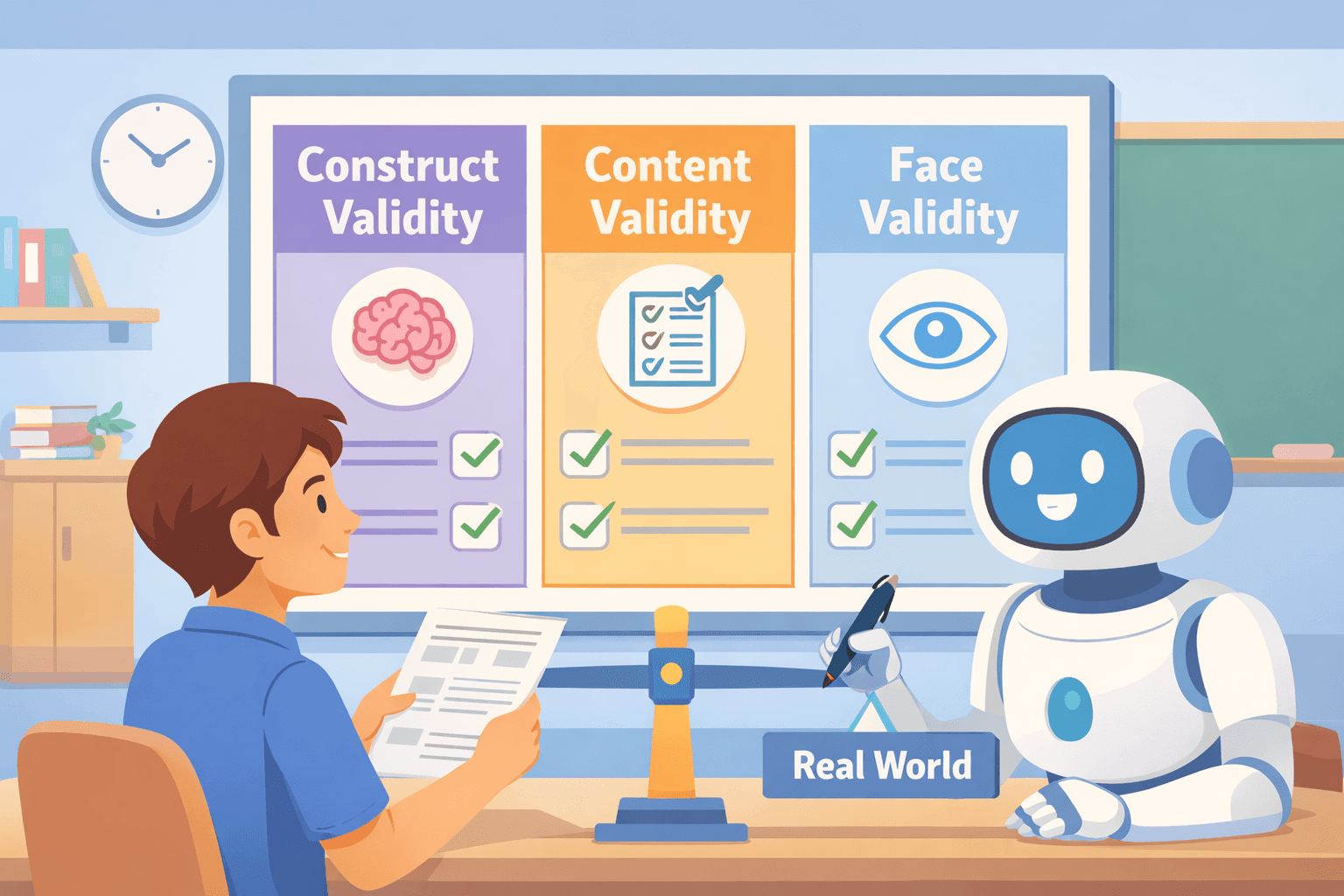
研究人員通常通過三種核心類型來評估這一點:建構效度、內容效度和表面效度。如需相輔相成地了解信度(以及它與效度的區別),請參閱我們的研究信度類型指南。
建構效度(Construct validity)是最深層的檢驗。它檢查您的工具是否真正衡量了您想要的內容,例如「韌性」或「客戶忠誠度」,而不是其他不相關的概念。
內容效度(Content validity)關乎覆蓋範圍。它確保您的測量涵蓋了該概念的所有重要方面。一份優秀的工作滿意度調查應該探討薪酬、工作環境和職業發展,而不僅僅是其中之一。
表面效度(Face validity)是最簡單的。這是一種表面層級的審查:該工具在外觀上是否看起來衡量了它應該衡量的事情?雖然這較為主觀,但過低的表面效度可能會削弱受訪者的信任。
例如,一個優良的抑鬱症測試應該檢視多種症狀,包括情緒和身體層面,而非僅僅局限於悲傷情緒。
效標關聯效度:現實世界的考驗
這種類型將理論付諸實踐。效標關聯效度(Criterion validity)將您的測量結果與外部、現實世界的基準進行對比。它主要有兩種形式:
預測效度(Predictive validity)探討您的工具能否預測未來的結果。一個有效的的大學入學考試應該能夠預測第一學年的平均積點(GPA)。
同時效度(Concurrent validity)檢視您的工具是否與同時進行的已知測量保持一致。一種新型、快速的焦慮篩查工具,其得分應與已確立、更長的臨床訪談得分呈相關關係。
效度類型 | 檢驗內容 | 範例 | 強度 |
建構效度 | 理論準確性 | 這項測試真的能衡量智力嗎? | 高 |
內容效度 | 覆蓋完整性 | 我們的調查是否包含工作滿意度的所有關鍵方面? | 中 |
表面效度 | 表面觀感 | 這份問卷看起來與主題相關嗎? | 低 |
效標關聯效度 | 外部對比 | 我們的新風險評分是否與已知的患者結果相匹配? | 高 |
上表展示了效度如何從簡單的表面效度開始,逐步走向更強大的、基於證據的檢驗。
<ProTip title="💡 專家貼士:" description="在審查調查問題時,引入專家小組評估。他們能協助確認您的測量是否涵蓋了該概念的全部內容。" />
實驗與設計效度

當一項研究旨在證明 A 導致 B 時,其實驗效度便面臨考驗。如果您在不操縱變量的情況下分析關係,我們的相關性研究概述將解釋您可以得出和不能得出哪些結論。這是展示因果關係的基本途徑,在臨床試驗和教育研究等領域中極為重要。
根據美國疾病管制與預防中心(CDC)的說法,如果您的研究規劃不周,您將無法判斷結果是源於您的努力,還是純屬偶然。簡而言之,薄弱的研究使您無法證明您的工作確實帶來了改變。
內部效度:抽離出因果關係
這是實驗邏輯的核心。內部效度(Internal validity)探討:您所做的改變是否切實產生了您所看到的結果,抑或是其他因素可以解釋這一切?研究人員致力於控制那些會混淆這種關聯的「威脅」。
在測試這些之前,明確的研究焦點至關重要。如果您不確定如何正確建構您的研究,這篇關於如何撰寫研究問題的指南可以幫助您,確保您的效度工作建立在堅實的基礎上。
常見的威脅包括:
選擇偏差(Selection bias),即各組群在研究開始時並不對等。
歷史效應(History effects),即外部事件影響了結果。
儀器變化(Instrumentation changes),例如在研究中期更換了測量工具。
參與者流失(Participant attrition),即流失率使最終樣本產生偏差。
在藥物試驗中,研究人員必須確保藥物確實是幫助患者康復的因素。如果患者在同一時間也開始改善飲食,那麼就很難說他們好轉是因為藥片還是因為新飲食。
您可以閱讀對研究效度及其不同類型更深入的解釋,以更全面地了解這些威脅如何影響研究的準確性。
<ProTip title="💡 專家貼士:" description="隨機化(Randomization)是在實驗研究中保護內部效度最強有力的方法之一。" />
外部效度:拓展至實驗室之外
如果內部效度問的是「在這裡有效嗎?」,那麼外部效度問的則是「在外部世界有效嗎?」它評估的是您的研究發現能在多大程度上廣泛應用於其他人群、其他地方或其他時間。
這兩者之間往往存在衝突。一項實驗在實驗室中可能進展得非常完美,但如果設定過於「虛假」,其結果在現實世界中可能不會以同樣的方式呈現。
相比之下,大規模的全國性調查通常具有較強的外部效度,但在控制每個變量上面臨更多挑戰。
生態效度:現實生活的考驗
這是外部效度的一個特定方面。生態效度(Ecological validity)側重於研究環境和任務在多大程度上自然地反映了您試圖理解的現實世界背景。這在心理學、教育和用戶體驗研究中至關重要。
研究兒童在真實課堂中如何解決問題,比將他們帶入一個無菌、安靜的實驗室執行相同任務具有更高的生態效度。前者捕捉到了屬於真實現象一部分的噪音、干擾和社交動態。
<ProTip title="💡 專家貼士:" description="實地研究(Field studies)可以提高生態效度,因為它們是在更自然的環境中測試行為。" />
高階效度證據
一旦確立了基本類型,您就可以通過高階效度證據為您的測量建立更強有力的依據。這些方法通過提供來自不同方向的收斂證據來鞏固建構效度。
收斂效度和區別效度
將其視為對您理論概念的雙重檢查。
收斂效度(Convergent validity)提供了證據,證明您的測量結果與旨在評估相同或極其相似概念的其他工具具有高度相關性。如果您新開發的「韌性量表」與現有的、值得信賴的韌性問卷毫無關聯,那就有問題了。
區別效度(Discriminant validity)提供了證據,證明您的測量結果與旨在測量理論上不同概念的工具*不*存在強相關性。您的韌性量表不應產生與一般幸福感調查完全相同的分數。
例如,設計良好的焦慮量表的分數應該與壓力問卷顯示出有意義的關係(收斂效度)。
然而,這些焦慮分數不應與微積分考試的分數密切相關(區別效度)。這種模式證實了「焦慮」在您的研究中是一個獨特且有意義的概念。
統計結論效度
這種類型關乎的不是您在測量*甚麼*,而是您*如何*分析數據。統計結論效度(Statistical conclusion validity)探討您的統計檢定是否正確設置,以便在確實存在真實關係或效應時能夠檢測出來。
它側重於避免兩種關鍵錯誤:錯誤地發現了並不存在的效應(第一型錯誤),以及遺漏了確實存在的效應(第二型錯誤)。
如需更具實踐性的分析,請參閱這篇關於效度類型與範例的指南,它將統計推理與真實的研究設計聯繫起來。
流行病學或經濟學等定量領域的研究人員對此非常關注。這涉及檢查回歸或相關等檢定的假設、確保充足的樣本大小(統計檢定力),並正確解讀 p 值和信賴區間。
統計結論效度薄弱意味著,無論您的測量工具多麼優秀,您都無法信任分析的基本數值結果。
<ProTip title="💡 專家貼士:" description="樣本量不足會削弱統計結論效度,即使研究設計看起來很穩固也是如此。" />
研究中的內部效度與外部效度
在進行研究時,研究人員試圖同時做兩件事:展示因果關係,並確保結果在現實生活中仍然有意義。這正是內部效度與外部效度之間的核心張力所在。
內部效度關乎控制和精確性。它探討:「我能否確信,是*我的*干預措施在這個特定的實驗中引起了我所觀察到的變化?」它需要嚴格管理的條件來排除其他解釋。
外部效度關乎寬度和應用。它探討:「這一發現是否適用於其他人群、其他地方或其他時間?」它追求現實世界的相關性。
這其中存在著固有的權衡。一個完美受控的實驗室實驗(每個變量都受到嚴格限制)可以最大化內部效度。但其人工設定可能會削弱外部效度,讓人難以確定結果是否適用於實驗室之外。
在真實環境中(如課堂或社區)進行的研究感覺更自然,也更符合現實生活。但由於控制力較弱,因此很難確保因果關係。
正確的平衡完全取決於您的研究問題。測試新藥機制的藥理學家會優先考慮內部效度;而規劃社區健康計劃的公共衛生官員則需要更強的外部效度。
要素 | 內部效度 | 外部效度 |
首要焦點 | 確立因果關係 | 概括研究結果 |
典型環境 | 受控實驗室 | 現實世界環境 |
主要優勢 | 高精準度與高度控制 | 高現實世界適用性 |
一項設計良好的研究並不需要在兩大維度上都獲得滿分。相反,研究應選擇對其目標最為關鍵的效度類型,然後圍繞該選擇來設計研究,並接受隨之而來的局限性。
<ProTip title="💡 專家貼士:" description="在建立研究方法之前決定您的效度優先級。有些研究需要更多的控制,而有些則需要更多的現實世界相關性。" />
學術討論中的效度與現實世界的混淆
效度理論雖然清晰,但應用起來卻很繁雜。即使是研究人員,在字面定義上也並不總是能達成一致,而且這些概念往往相互重疊。正因如此,您在教科書中學到的知識,並不總是與實際研究中的應用方式完全契合。
學生和剛步入研究生涯的研究人員經常會遇到相同的阻礙。在 Reddit 的 r/statistics 等論壇上,一個熱門討論話題就是混淆了建構效度和效標關聯效度。
人們通常會遇到同樣的問題:混淆不同類型的效度、在抽象概念中掙扎,並試圖應對繁雜的情況。缺乏具體範例,理論便會顯得空洞脫節。
而在 Quora 等平台上,則能看到不同的解決方式。當地的專家經常試圖通過提供結構化、逐步的框架工作來彌補這一差距。
他們側重於研究人員用以證明結果有效性的數學工具,如因素分析或回歸分析。這種從「它是甚麼」到「如何證明它」的轉變,對於將理論轉化為實踐至關重要。
在社交媒體上,尤其是 X (Twitter) 上,對話變得更加簡化。效度被提煉成精簡、易於分享的建議:「去量度你意圖量度的事情。」
雖然這話沒錯,但這個口號剝離了所有該有的複雜性。它無法幫助某人去決定:他們的研究是需要更好的內部控制,還是需要更廣泛的抽樣。
YouTube 上的教學短片呈現了另一種挑戰。為了將主題納入短片播放長度中,創作者往往會過於簡化,並遺漏了重要的細節。
這些影片底下的評論非常能說明問題。許多人在尋求更清晰、更詳細的解釋;也有人感到沮喪,因為當他們試圖在自己的研究或作業中應用該簡化模型時,往往並不奏效。
大眾的需求並不是更多的理論,而是將其翻譯成研究設計與評論的實際語言。
<ProTip title="💡 專家貼士:" description="用真實的研究案例來測試效度概念,而不要僅僅依賴定義。這樣可以更容易發現其中的差異。" />
為研究人員量身定制的效度檢查清單框架
以下是一個實用的框架工作,可用於確保您在設計研究時涵蓋了所有不同類型的效度。
如何徹底執行
具體說明您正試圖量度的內容。
確保您的工具切實量度了該概念。
尋找研究內部可能干擾結果的任何因素。
判斷您的研究結果在多大程度上可以應用於其他地方。
進行數據計算,以檢驗您的測量是否一致。
檢視您的結果是否確實符合您最初的理論。
為了使您的研究符合正式標準,請檢視官方的 APA 研究報告標準 (JARS),該標準概述了透明且有效報告的最佳實踐。
其用途為何 想像您正在建造一座橋樑。這份清單中的每次檢查就像增加一根支撐樑。如果您跳過其中一項,整個結構就會變得更加脆弱。
採用這種方法有助於減少偏差,並使您的研究更具可靠性。它適用於心理學、經濟學等多個領域,能讓您的結果更容易贏得信任。
<ProTip title="💡 專家貼士:" description="在全面收集數據之前先進行一項先導研究(pilot study),以便及早發現效度問題。" />
將有效性轉化為清晰、可靠的研究
您可能曾試圖理清不同效度類型,但仍對自己的研究是否經得起推敲感到不確定。這很容易讓人產生困惑,甚至心生懷疑。
<CTA title="將有效性轉化為更清晰的研究寫作" description="使用 Jenni 來解釋您的研究設計、完善您的推理,並寫出更具說服力的學術章節。" buttonLabel="免費試用 Jenni" link="https://app.jenni.ai/register" />