
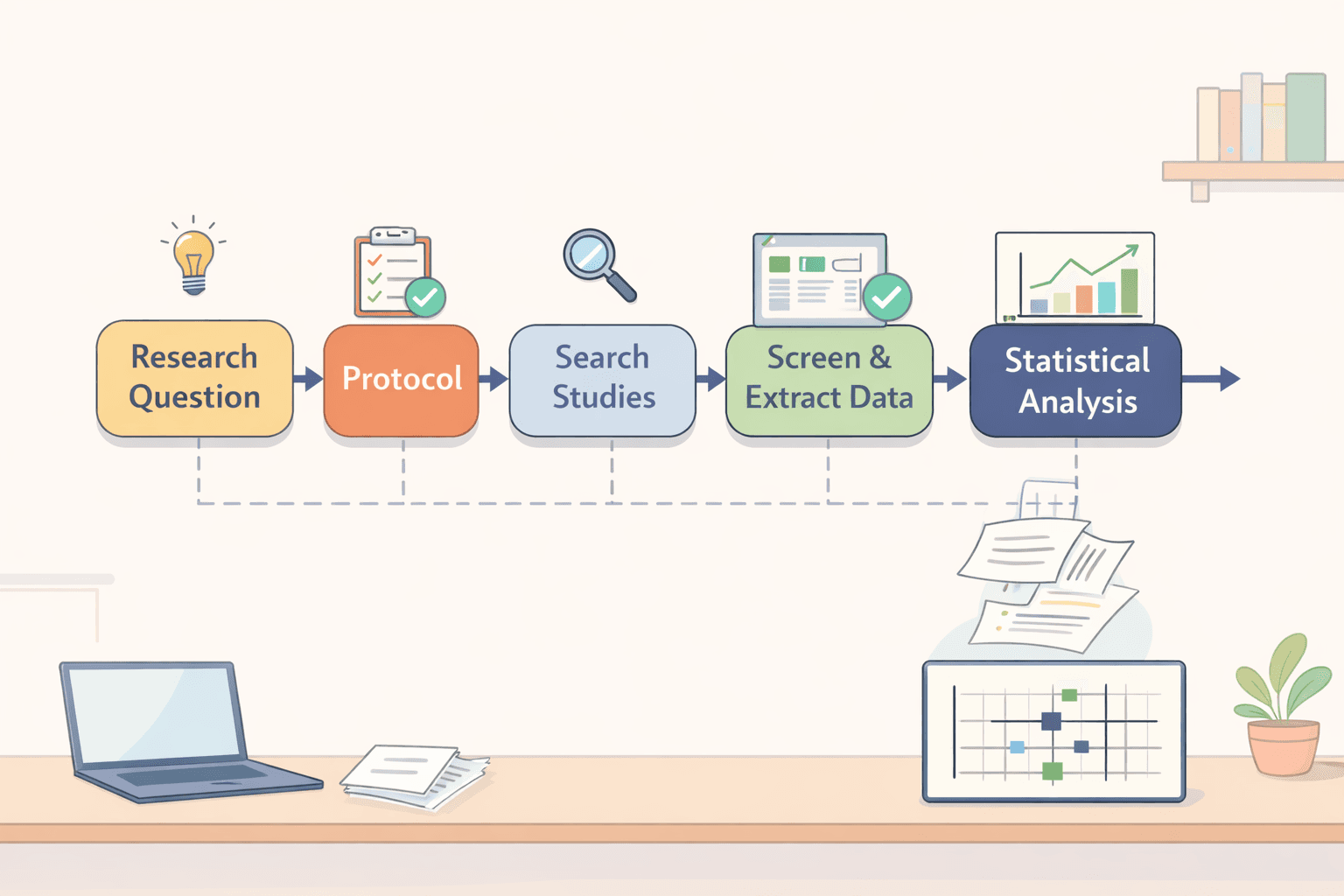
統合分析(Meta-analysis)結合了多項研究的結果,並將其合併為一個更具說服力的結果。這是一項關鍵的研究方法,特別是在醫學和心理學領域。
本指南涵蓋了從頭到尾的完整流程。我們將從建立研究問題開始,一路走到解讀最終的數據。您還將了解所需的工具以及需要注意的典型錯誤。如果您在進行定量合成的同時撰寫文獻探討敘述,AI 文獻探討與相關研究(RRL)生成器可以幫助您整理來源並撰寫背景內容。
<CTA title="清晰規劃您的統合分析" description="透過引導式 AI 大綱與清晰的步驟,系統化您的研究工作流程" buttonLabel="免費試用 Jenni" link="https://app.jenni.ai/register" />
什麼是統合分析?為什麼它很重要?
統合分析是一種合併多項研究數據的方法。透過這樣做,它能產生單一且更強有力的結果。較大且合併後的樣本量能使研究結果更具穩健性,且更不易受到偶然因素的影響。
《考克蘭指引》(Cochrane Handbook)指出,這種跨研究的數據合成所產生的證據,比任何單一研究所能提供的都更可靠。
關於系統性文獻回顧與統合分析如何協同工作的實用概述,可以參考這篇關於系統性文獻回顧與統合分析的指南。
此技術在多個領域中非常常見:
醫學
心理學
教育研究
簡單來說,這就像是把許多小型實驗合併,變成一個大型、更值得信賴的研究。
<ProTip title="💡 專家提示:" description="唯有在各研究測量相似結果時,統合分析才有用" />
步驟 1:定義清晰的研究問題
統合分析中的一切都取決於起始問題。如果問題含糊不清,整個項目從一開始就會失去焦點。
建立問題的好方法是使用 PICO 架構。它將問題拆分為四個部分:
Population(研究對象)
Intervention(干預措施)
Comparison(比較對象)
Outcome(研究結果)
例如:「對於50歲以上的成年人,[藥物 X] 是否比安慰劑更能降低血壓?」
做好這一步至關重要。您的具體問題決定了您要搜尋哪些研究、從中提取哪些資訊,以及如何進行分析。模糊的問題意味著您會收集到不一致的數據,而最終的結論也不會具有說服力。
步驟 2:制定並註冊研究計劃書
在您收集任何數據之前,您需要一個計劃。這個計畫被稱為研究計劃書(Protocol)。它是一份詳細的文件,提前鎖定了您的研究方法。其主要目標是防止偏誤,阻止您事後為了獲得更好的結果而改變研究方法。
您的計劃書應清楚說明以下幾個關鍵事項:
您的具體研究問題
納入或排除研究的確切規則
檢索文獻的完整策略
您計劃用於分析的統計方法
將此計劃書註冊在 PROSPERO 等公共平台上是一個很好的做法。這能讓您的整個過程對所有人公開透明。
提前做好這項工作有其實質原因。它可以防止對結果進行「挑揀(cherry-picking)」、使其他研究人員能夠重複您的研究,並讓您的最終分析更具公信力。
如果您仍在奠定研究基礎,閱讀篇敘述性文獻回顧可以幫助您在進入系統性方法之前,了解如何建構研究背景。
<ProTip title="📌 專家提示:" description="在搜尋研究之前撰寫您的計劃書,以避免偏誤" />
步驟 3:進行系統性的文獻檢索
統合分析的品質取決於是否找到了所有相關研究。不完整或有偏誤的檢索會使最終答案產生偏差。
您需要在對的地方尋找。主要數據庫是必不可少的:
PubMed
Scopus
Web of Science
Google Scholar
不要僅限於已發表的期刊文章。您還應該搜尋「灰色文獻」,例如未發表的學位論文、會議論文和研究註冊處,以避免發表偏誤。有關通常在統計前進行的文獻回顧流程之更完整說明,請參閱這篇系統性文獻回顧逐步指南。
建立有效的檢索需要策略。您將使用特定的關鍵字,並結合布林邏輯運算子(AND、OR),同時通常會採用數據庫的控制詞彙,例如 PubMed 中的 MeSH 詞彙。
為了有效地規劃這個過程,您可以遵循如何撰寫文獻回顧大綱來組織檢索詞和納入邏輯。
例如,檢索式可能看起來像:"hypertension" AND "randomized controlled trial" AND "antihypertensive agents"。
這一步至關重要,因為如果您遺漏了重要研究,您的合併結果可能會完全錯誤。一項透徹且有記錄的檢索是您對抗此問題的最佳防禦。
步驟 4:篩選並選擇研究
檢索完成後,您將獲得一份龐大的潛在研究清單。下一步工作是根據您在計劃書中設定的嚴格規則對它們進行篩選。
這主要分為兩個階段。首先,您快速瀏覽所有的標題和摘要。然後,對於似乎相關的研究,您取得並閱讀全文。
在每個步驟中,您都要套用預先定義的納入和排除標準,以決定哪些保留、哪些排除。常見的篩選標準有哪些?
研究設計的類型通常是第一步,許多統合分析僅納入隨機對照試驗。其他規則可能涉及最小樣本量、測量結果的特定方式或研究對象群體。
由兩個人獨立進行這項篩選被認為是最佳做法。這能減少個人偏見。當兩位評審對某項研究有意見分歧時,他們會進行討論以達成共識。
整個篩選過程應以可視化方式記錄,通常使用 PRISMA 流程圖。這張圖表精確顯示了找到了多少項研究、移除了多少項以及原因,使您的方法完全透明。
步驟 5:提取並整理數據
這是需要手動完成的工作。您要進入每項納入的研究,並提取出計算所需的特定數值。它能將數頁的研究報告轉化為結構化的數據集。
一般來說,您需要從每項研究中提取幾項關鍵資訊:
每組的樣本量
結果的平均值和標準差
計算出的效果量(如 Cohen's d 或優勢比 Odds Ratio)
基本研究特徵(年份、設計、研究對象)
關於這些數據點在真實研究中如何運用的更深層解釋,可以在這篇關於臨床研究中的統合分析的文章中找到,該文介紹了實際應用與解讀方式。
您需要將這些內容整理到表格或電子試算表中。例如:
研究 | 樣本量 | 效果量 |
研究 A | 100 | 0.5 |
研究 B | 150 | 0.7 |
確保這一步的正確性是毫無妥協餘地的。這裡一個簡單的打字錯誤或讀錯數字,會直接影響到您的分析並扭曲最終結果。這就是為什麼使用標準化表格並由第二個人驗證提取的數據是如此重要。
<ProTip title="🧠 提醒:" description="使用標準表單以保持數據提取的一致性" />
步驟 6:評估研究品質與偏誤
您不能假定找到的每項研究都是良好進行的。這一步是為了判斷您即將合併的每項證據的內部可信度。
研究人員使用標準化工具來使這種評估保持一致。常見的工具有 Cochrane 偏誤風險工具(用於隨機試驗)和 ROBINS-I(用於非隨機研究)。
這些工具有助於您檢查可能扭曲研究結果的特定問題,例如:
選擇偏誤(Selection bias): 參與者是如何被分配到群組的?
測量偏誤(Measurement bias): 對每個人結果的測量是否公正?
報告偏誤(Reporting bias): 作者是否隱瞞了不利的結果?
您要如何處理這些資訊?被判定為高偏誤風險的研究是棘手的。它們可能會被完全排除,或者更常見的是,其影響會被測試。敏感度分析(Sensitivity analysis)會在不納入這些較弱研究的情況下重新運行主要結果,以判斷結論是否會改變。
步驟 7:進行統計分析

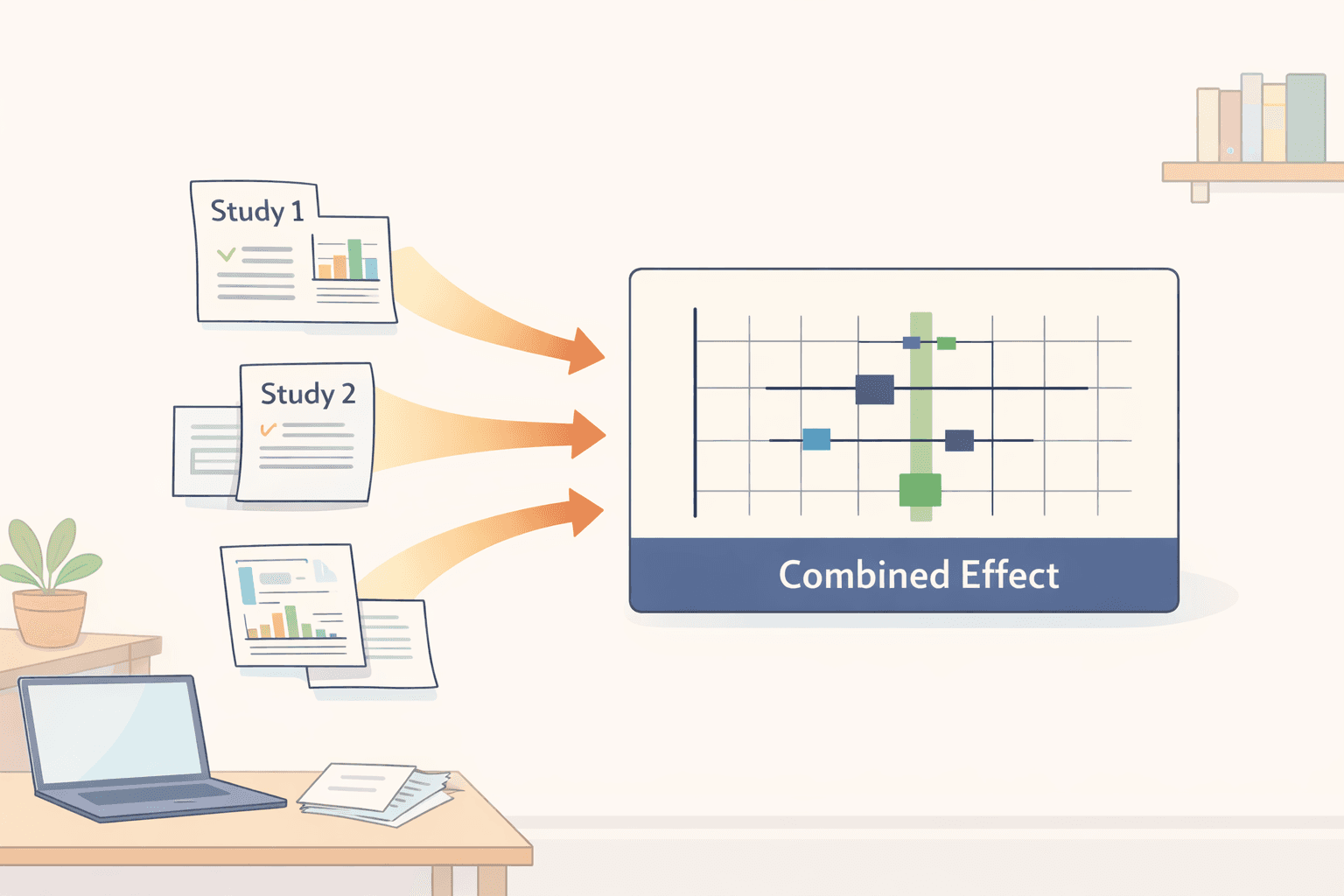
在這裡,您將所有研究中的數據合併為單一結果。
首先,您要為數據選擇合適的統計指標(效果量)。常見的有優勢比(用於是/否二分法結果)、風險比(Risk ratio)或標準化平均差(用於比較平均值)。
接著,您要選擇統計模型。如果您認為所有研究都在估算一個真實的效果,則適用固定效果模型(Fixed-effect model)。隨機效果模型(Random-effects model)更為常用,它考慮到真實效果在不同研究之間可能會有些許差異。
關於這些統計原理的經典解釋,可以在這篇統合分析原則與程序資源中找到,其中詳細介紹了結果合併與解讀的方法。
分析的一個關鍵部分是檢查異質性(Heterogeneity),即各研究結果彼此之間的分歧程度。I² 統計量對此進行了量化。低於 25% 的值表示分歧程度低,而高於 50% 的值則表示高異質性。
如果您的 I² 值很高,這意味著各研究給出了非常不同的答案。您的合併結果仍然有意義,但您必須謹慎詮釋並解釋其變異性。
步驟 8:建立並解讀視覺化圖表
統合分析的結果通常以圖表形式展示。這不僅是為了美觀,它還能讓冗長的統計結果對任何閱讀報告的人都一目了然。
森林圖(Forest plots) 這是您會看到最常見的圖表。森林圖能同時呈現幾件事:
它顯示了納入分析的每項獨立研究的效果量和信賴區間。
它展示了所有這些研究合併後的「彙總(pooled)」效果量。
視覺化佈局能讓您迅速看清哪些研究具有共識、哪些是離群值,以及整體結果的精準度如何。
漏斗圖(Funnel plots) 研究人員使用這種類型的圖表來檢查一個特定問題:發表偏誤(Publication bias)。這指的是具有陽性或顯著結果的研究比具有陰性或無趣結果的研究更容易被發表的傾向。
對稱的倒漏斗形狀表示這種偏誤極小。
如果圖表看起來不對稱或有缺口,這是一個警訊,表明分析中可能遺漏了重要數據,這可能會扭曲最終的結論。
為什麼視覺化圖表很重要 簡單來說,一張製作精良的圖表可以在幾秒鐘內傳達可能需要數個段落才能解釋清楚的內容。它們將成列的數字轉化為更容易理解、質疑和信賴的故事。
<ProTip title="📊 專家提示:" description="使用森林圖快速傳達整體研究結果" />
步驟 9:進行進階分析
來自統合分析的基本合併結果很有用,但通常這並不是全部的故事。為了獲得更清晰、更詳細的畫面,研究人員會進行進階分析。這些技術能測試結果的穩健性,並深入探究數據背後的「原因」。
常用方法
次群組分析(Subgroup analysis): 這會將數據分成不同類別。您可能會比較針對男性與女性的研究結果,或者使用高劑量與低劑量的研究。它回答了「效果是否會因不同類型的人或在不同條件下而改變?」的問題。
敏感度分析(Sensitivity analysis): 在這裡,您要檢查您的主要發現有多穩固。如果移除最大的那項研究會發生什麼事?或者排除偏誤風險高的研究會怎樣?如果結論因此逆轉,說明您原來的結果是脆弱的。如果保持穩定,您就可以對其更有信心。
統合迴歸(Meta-regression): 這是一種更具統計學意義的方法。它不僅僅是將研究進行分組,而是試圖對特定的研究特徵(例如參與者的平均年齡或發表年份)與效果量之間的定量關係進行建模。
應用範例 假設您的統合分析發現一項新的輔導計劃有助於學生。次群組分析可能會揭示它只對高中生有用,對國中生則沒有幫助。
敏感度分析可能會顯示,該結果完全取決於一項設計不佳的研究。統合迴歸則可能表明,該計劃的有效性隨著其推行年份的增加而稍微下降。
這些分析不僅僅是合併數據,更是對數據進行深入剖析。它們有助於解釋為什麼研究結果會存在變異,並精確地告訴您在何處以及對誰而言,證據是最強有力的。
步驟 10:清晰報告您的研究結果
一項進行得再好的統合分析,也可能會因為一份寫得不好的報告而功虧一簣。清晰、有條理的報告是讓您的工作對其他科學家而言具備公信力、實用性且值得信賴的關鍵。
遵循 PRISMA 指引 現在大多數研究人員都使用 PRISMA 架構。這是一份列出應包含內容的清單。如果您在報告前仍在釐清不同回顧類型之間的區別,這篇關於統合分析與系統性文獻回顧的比較指南能幫助確保您的架構和術語準確無誤。
流程圖: 一張視覺化圖表,展示您是如何從搜尋數千條記錄到最終納入僅存的少數幾項研究。它記錄了您的每一個決定。
研究表格: 整理了每項納入研究的設計、參與者和關鍵結果的摘要。
統計結果: 彙總的效果量、信賴區間和異質性檢定,即您分析中的所有數據。
研究限制: 對您文獻回顧缺點的誠實討論,例如潛在的發表偏誤或低品質的來源研究。
使用 PRISMA 不僅是一種形式。它迫使您展示您的工作,使其他人能夠對其進行適當的評估,甚至在想要時重複您的研究。
寫作技巧
力求簡明。直奔主題。
詳細解釋您的研究方法部分,以便其他人能夠遵循。
堅持您數據實際呈現的內容。不要誇大結論或做超出證據之外的推測。
常見挑戰及處理方式
坦白說:進行統合分析很難。這是一個技術性強、耗時的過程,尤其是在您剛開始的時候,遇到障礙是很正常的。
頻繁遇到的挑戰
處理缺失數據: 這很常見。作者可能沒有報告您所需的確切數字。您必須與他們聯繫、進行估算,有時甚至需要完全排除該研究。
管理異質性: 當您納入的研究顯示出截然不同的結果時,將它們合併感覺是不對的。您需要判定這種變異是否在可接受範圍內,或者它是否會使整個分析失效。
學習統計軟體: 電子試算表是不夠用的。您需要專業工具,而且它們的學習曲線非常陡峭。
實用的解決方案
使用正確的工具: 像 R(帶有 metafor 或 meta 等套件)或 RevMan 等軟體就是為此而設計的。它們能處理複雜的計算。
從小處著手: 第一次嘗試時,不要試圖合成五十項研究。先從一個聚焦的問題和可管理的五到十篇論文開始練習。
尋求幫助: 及早諮詢統計學家或有經驗的同行。這可以為您節省數月的挫折時間。
客觀事實: 一項合格的系統性文獻回顧和統合分析絕不是一個週末就能完成的項目。這是一項重大的研究工作。
大多數團隊報告稱,要做好這項工作需要花費三個月到整整一年的時間。這個過程需要耐心、仔細的組織以及邊做邊學的意願。
<ProTip title="⚠️ 專家提示:" description="切勿指望一蹴而幾,統計分析的準確性遠比速度重要" />
進行統合分析的工具
您對軟體的選擇可以使過程變得更加順利或困難得多。正確的工具能處理複雜的統計數據,讓您能專注於科學研究。如果您在篩選和提取過程中還需要管理龐大的 PDF 和引用文獻庫,針對研究人員的 Zotero 與 Mendeley 整合可以幫助您保持一切井然有序。
熱門軟體
R (搭配 metafor 或 meta 套件)
RevMan (來自 Cochrane)
Stata
Comprehensive Meta-Analysis (CMA)
快速比較
工具 | 費用 | 最適合用於 |
R | 免費 | 進階使用者,完全客製化 |
RevMan | 免費 | 初學者,Cochrane 風格的文獻回顧 |
Stata | 付費 (授權) | 專業研究團隊 |
CMA | 付費 (授權) | 偏好滑鼠點選介面的研究人員 |
這些工具沒有一個是能立即上手的。每個工具都有自己的學習曲線。如果您是新手,從 RevMan 這樣更簡單、有引導的工具開始,通常是在面對更強大選擇之前建立信心的最佳方式。
如何成功進行統合分析
進行統合分析需要系統性的規劃、仔細的數據處理以及清晰的報告。每一步都建立在基礎之上,形成一個可靠的研究過程。
<CTA title="將研究轉化為清晰的寫作" description="輕鬆將複雜的統合分析工作流程組織成結構化的論文" buttonLabel="免費試用 Jenni" link="https://app.jenni.ai/register" />
透過遵循循序漸進的方法,您可以產生準確且有意義的結果。像 Jenni 這樣的工具透過幫助您建構想法、保持條理並清晰傳達研究發現,來支持這一過程。