







초안부터 동료 검토 피드백까지, 세 단계로
초안을 여기에 놓으세요
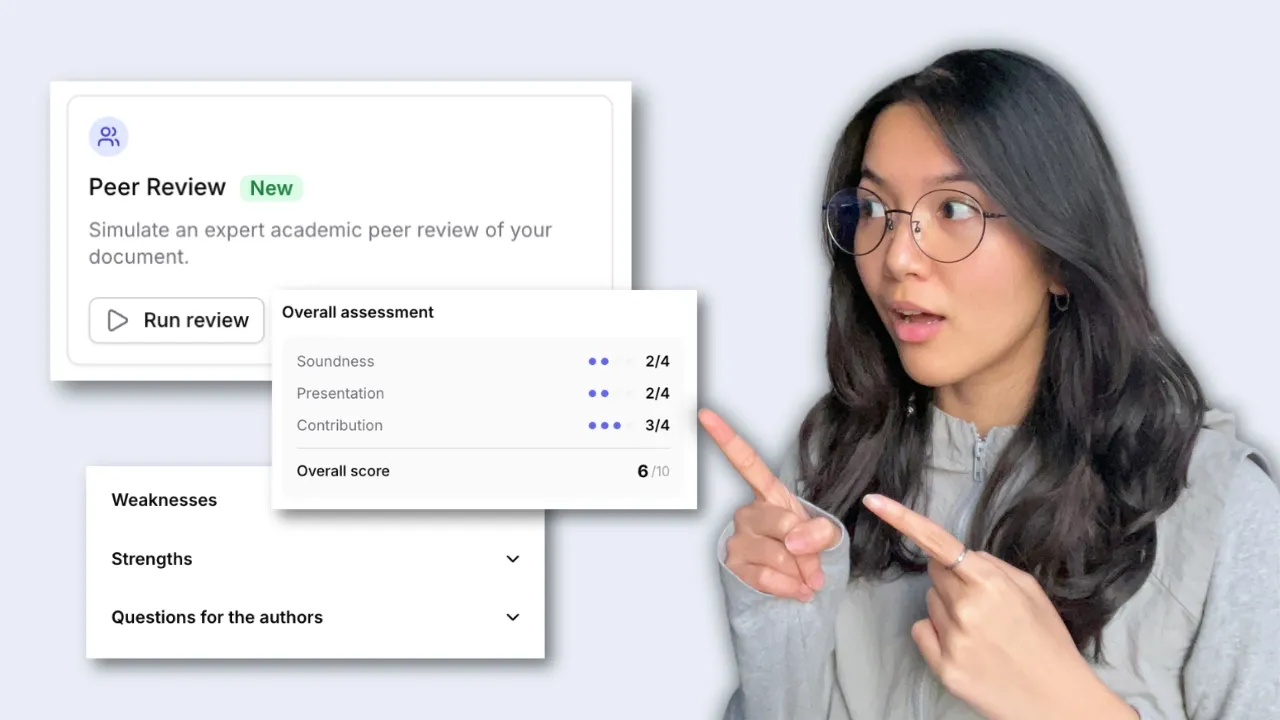
동료 검토 실행
Jenni는 표준 동료 검토 기준에 따라 원고를 검토하고, 핵심 영역을 평가하며, 초안에 바로 적용할 수 있는 개선 사항을 표시합니다.
해결하고, 다시 실행하고, 반복하세요
댓글은 수정이 필요한 정확한 구절에 바로 연결되어 원고에 표시됩니다. 각 문제를 해결하고 점수가 향상되는 것을 확인하세요.
실제 동료 검토를 확인하세요
Jenni가 실제 원고를 읽고, 평가 기준에 따라 점수를 매기며, 각 섹션에서 보완이 필요한 부분에 댓글을 남기는 모습을 확인해 보세요.
학문적 엄밀성을 위해 설계됨
대부분의 AI 도구는 일반적인 글쓰기 피드백을 제공합니다. Peer Review는 심사자가 하듯 원고를 평가합니다.

전체 원고를 읽습니다
Peer Review는 초안을 처음부터 끝까지 꼼꼼히 읽어 모든 주장, 모든 방법 메모, 그리고 모든 전환을 파악하므로 피드백이 문서 전체를 반영합니다.

리뷰어들이 사용하는 동일한 기준
Peer Review는 주요 학술지에서 사용하는 것과 동일한 심사 양식을 작성하며, 타당성, 기여도, 발표에 대한 점수와 서면 피드백을 제공합니다.

구절에 연결된 댓글
Jenni는 모든 댓글을 특정 문장에 연결하고, 이유와 함께 सुझ정 수정 방법도 제시합니다. 단순히 뭔가 이상하다는 것만이 아니라, 무엇을 어디에서 바꿔야 하는지 정확히 알 수 있습니다.
제출 전 전체 인용 검토
Peer Review는 검토자가 문제를 발견하기 전에 문제를 찾아내는 4가지 검토 도구 중 하나입니다. 제출 전에 완전하게 점검하려면 함께 실행하세요.
Peer review8 / 10
Manuscript scored against a peer-review rubric with reviewer comments on each section.
Soundness
3/4
Presentation
4/4
Contribution
3/4
Results
Strengths
Weaknesses
Claim confidence10 issues
The claim confidence analysis addressed issues of redundant, weak, or missing citations, alongside instances of contradiction in citation arguments.
Misrepresented
Contradicted
3Unsupported
4Weakly supported
2Overstated
Unverifiable
Outdated
2Self-citation heavy
Predatory source
Citation mismatch
1Proofread18 edits
Whilst generally sound, the text contains some areas for improvement to comply with academic best practices.
Word choice
AllThe majority of participants reported improved outcomes.
Formality
Yang (2024) found a negative correlation which was interesting..
Grammar
These results indicate that early intervention be effective. appears to be effective.
Transitions
Also, In addition, Jones (2022) found similar results.
Overgeneralized
AllThe majority of participants reported improved outcomes.
The results provesuggest that X has an effect on Y.Tone of voice22 notes
Suggestions across vocabulary, syntax, punctuation, tone and flow to keep a consistent academic voice.
All Suggestions
22Vocabulary
6Syntax
5Punctuation
4Tone
3Flow
4동료 검토
신뢰를 주장하세요
교정하다
톤 앤 보이스


저희 사용자는 100개 이상의 저널에 논문을 게재했습니다
IEEE, Springer, Elsevier 같은 학술지에 게재된 실제 연구 — Jenni로 기획하고 작성하세요.
