によって
ジャスティン・ウォン
—
ステップ・バイ・ステップで進めるメタ分析の実施方法

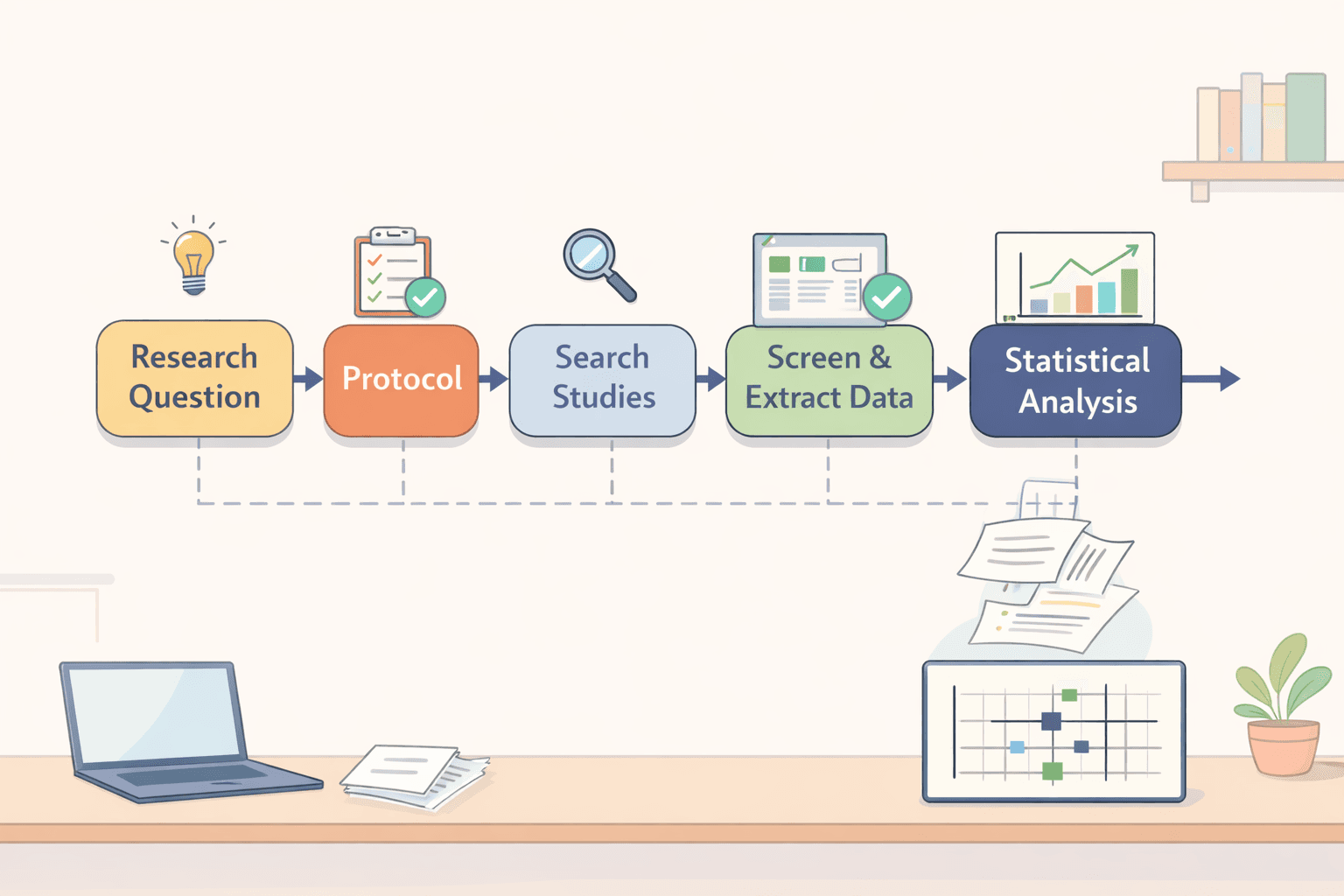
メタ分析(メタアナリシス)は、多くの研究から得られた結果を統合し、1つのより強力な結果へとまとめる手法です。これは、特に医学や心理学において重要な研究方法となっています。
このガイドでは、プロセスの最初から最後まですべてをカバーしています。研究課題の作成から、最終的な数値の解釈まで順を追って説明します。また、必要なツールや注意すべき一般的なエラーについても紹介します。定量的な統合と並行してレビューのナラティブを起草している場合は、AI Literature Review & RRL Generatorが情報源の整理や背景の執筆に役立ちます。
<CTA title="メタ分析を明確に計画する" description="ガイド付きのAIアウトラインと明確なステップで研究ワークフローを構造化します" buttonLabel="Jenniを無料で試す" link="https://app.jenni.ai/register" />
メタ分析とは何か、なぜ重要なのか
メタ分析とは、複数の研究から得られたデータを統合するための方法です。これを行うことで、単一の、より強力な結果を生み出すことができます。統合によってサンプルサイズが大きくなるため、結果の頑健性が高まり、偶然による影響を受けにくくなります。
コクラン・ハンドブック(Cochrane Handbook)によると、このように複数の研究にわたるデータを統合することで、個々の研究よりも信頼性の高いエビデンスを構築できるとされています。
系統的レビュー(システムレビュー)とメタ分析がどのように連携するかについての役立つ概要は、こちらの系統的レビューとメタ分析に関するガイドで見ることができます。
この手法は、以下のようなさまざまな分野で一般的に使われています。
医学
心理学
教育研究
簡単に言えば、多くの小さな実験を集めて、1つの大きくて信頼性の高い研究にするようなものです。
<ProTip title="💡 プロのヒント:" description="メタ分析は、各研究が同様のアウトカムを測定している場合にのみ有用です" />
ステップ 1: 明確な研究課題を定義する
メタ分析のすべては、最初の問いにかかっています。それが曖昧であると、プロジェクト全体が最初から方向性を見失ってしまいます。
問いを構築するための優れた方法として、PICOフレームワークがあります。これは問いを以下の4つの要素に分解します。
Population(対象患者・集団)
Intervention(介入・要因)
Comparison(比較対照)
Outcome(アウトカム・評価項目)
例えば、「50歳以上の成人において、[薬物X]はプラセボよりも血圧を低下させるか?」といった問いです。
これを正しく設定することが極めて重要です。定義した問いによって、どの研究を検索し、どのような情報を抽出し、どのように分析を実行するかが決定されます。曖昧な問いでは一貫性のないデータが集まることになり、最終的な結論も説得力を欠くものになります。
ステップ 2: プロトコルを作成し登録する
データを1つでも収集し始める前に、計画を立てる必要があります。この計画はプロトコルと呼ばれます。これは事前に方法論を確定させるための詳細な文書です。主な目的はバイアスを防ぐことであり、後から好都合な結果を得るためにアプローチを変更することを防ぎます。
プロトコルには、いくつかの重要な事項を明確に記載する必要があります。
具体的な研究課題
どのような研究を含め、あるいは除外するかについての厳密な基準
文献検索の完全な戦略
分析に使用する予定の統計的手法
このプロトコルをPROSPEROなどの公開プラットフォームに登録することをお勧めします。これにより、プロセス全体が誰の目にも透明なものになります。
この作業を事前にこなしておくことには具体的なメリットがあります。結果の「良いとこ取り(チェリーピッキング)」を防ぎ、他の研究者があなたの作業を再現することを可能にし、最終的な分析の信頼性を大幅に高めることができます。
まだ基礎を固めている段階であれば、系統的な手法に進む前に、ナラティブ・レビューを確認して、研究の文脈がどのように構成されているかを理解すると役立ちます。
<ProTip title="📌 プロのヒント:" description="バイアスを避けるため、研究を検索する前にプロトコルを作成しましょう" />
ステップ 3: 系統的な文献検索の実施
メタ分析の質は、関連するすべての研究を見つけ出せるかどうかにかかっています。不完全であったり偏りのある検索を行うと、最終的な結論が歪んでしまいます。
適切な場所を探す必要があります。主要なデータベースは不可欠です。
PubMed
Scopus
Web of Science
Google Scholar
出版されたジャーナル論文だけにとどまらず、出版バイアスを避けるために、未出版の学位論文、学会発表用ペーパー、試験レジストリなどの「グレー文献」も検索する必要があります。統計処理の前に行われる一般的なレビュー手順の詳しい解説については、こちらの系統的文献レビューのステップバイステップガイドを参照してください。
効果的な検索を行うには戦略が必要です。キーワードを特定し、それらを論理演算子(AND, OR)で組み合わせ、さらにはPubMedのMeSH用語などのデータベースの統制語彙を活用します。
このプロセスを効果的に構築するために、検索語や組み込みロジックを整理する文献レビューのアウトライン作成方法を参考にするとよいでしょう。
例えば、検索式は次のようになります:"hypertension" AND "randomized controlled trial" AND "antihypertensive agents"。
このステップは極めて重要です。重要な研究を見逃してしまうと、統合された結果が完全に間違ったものになってしまう可能性があるからです。徹底的かつ文書化された検索こそが、それを防ぐ最善の防御策です。
ステップ 4: 研究のスクリーニングと選定
検索が完了すると、候補となる研究の膨大なリストが手元に残ります。次のステップは、プロトコルで設定した厳格なルールに基づいてこれらを絞り込むことです。
これは主に2つの段階で進められます。第一に、すべてのタイトルと抄録(アブストラクト)を素早くスクリーニングします。次に、関連性がありそうな研究についてフルテキスト(本文)を入手して読み込みます。
それぞれの段階で、事前に定義した適格基準(採用・除外基準)を適用し、どの研究を残し、どれを除外するかを決定します。一般的な基準にはどのようなものがあるでしょうか。
通常、最初に挙げられるのは研究デザインのタイプです(多くのメタ分析ではランダム化比較試験のみを対象とします)。その他のルールには、最小サンプルサイズ、アウトカムの具体的な測定方法、あるいは調査対象となった集団(人口統計学的属性など)が含まれます。
個人バイアスを減らすために、2人の担当者が独立してこのスクリーニング作業を行うことが推奨されています。2人の査読者の間で意見が食い違った場合は、議論を行って合意を形成します。
スクリーニングのプロセス全体を、通常はPRISMAフロー図などを用いて視覚的に記録する必要があります。この図は、最終的にいくつの研究が見つかり、除外され、その理由は何かを正確に示すものであり、手法の透明性を高めます。
ステップ 5: データの抽出と整理
これが実務的な作業となります。対象となった各研究から、計算に必要となる具体的な数値を抽出します。これにより、数ページに及ぶ論文が構造化されたデータセットに変換されます。
通常、各研究から以下のようないくつかの主要な情報を抽出します。
各群のサンプルサイズ
アウトカムの平均値と標準偏差
算出された効果量(コヘンのdやオッズ比など)
研究の基本的な特徴(発表年、デザイン、対象集団)
これらのデータポイントが実際の研究でどのように使用されるかについてのより詳細な説明は、実践的な応用と解釈を解説している臨床研究におけるメタ分析に関する記事で確認できます。
これを表やスプレッドシートに整理します。例:
研究 | サンプルサイズ | 効果量 |
研究 A | 100 | 0.5 |
研究 B | 150 | 0.7 |
これを正確に行うことは妥協できないポイントです。単純な入力ミスや数値の読み間違いがあると、それがそのまま分析に反映され、最終的な結果を歪めてしまいます。そのため、標準化されたフォームを使用し、二人目の人物が抽出されたデータを検証することが非常に重要です。
<ProTip title="🧠 リマインダー:" description="データ抽出の一貫性を保つために、標準化されたフォームを使用しましょう" />
ステップ 6: 研究の質とバイアスリスクの評価
見つかったすべての研究が、適切に実施されているとは限りません。このステップは、統合しようとしている個々のエビデンスの内部妥当性(信頼性)を評価するためのものです。
研究者は、評価の一貫性を保つために標準化された評価ツールを使用します。一般的には、Cochrane Risk of Biasツール(ランダム化試験用)やROBINS-I(非ランダム化試験用)などが使われます。
これらのツールは、研究結果を歪める可能性のある以下のような具体的な問題を特定するのに役立ちます。
選択バイアス: 参加者はどのように各グループに割り当てられたか?
測定バイアス: アウトカムはすべての人に対して公平に測定されたか?
報告バイアス: 著者らは不都合な結果を隠していないか?
この評価によって得られた情報はどのように扱われるでしょうか。バイアスリスクが高いと判定された研究は問題視されます。それらの研究を完全に除外することもあれば、より一般的には、それらの影響度をテストします。感度分析を行い、これら信頼性の低い研究を除外してメインの結果を再計算し、結論が変わるかどうかを確認します。
ステップ 7: 統計分析の実行

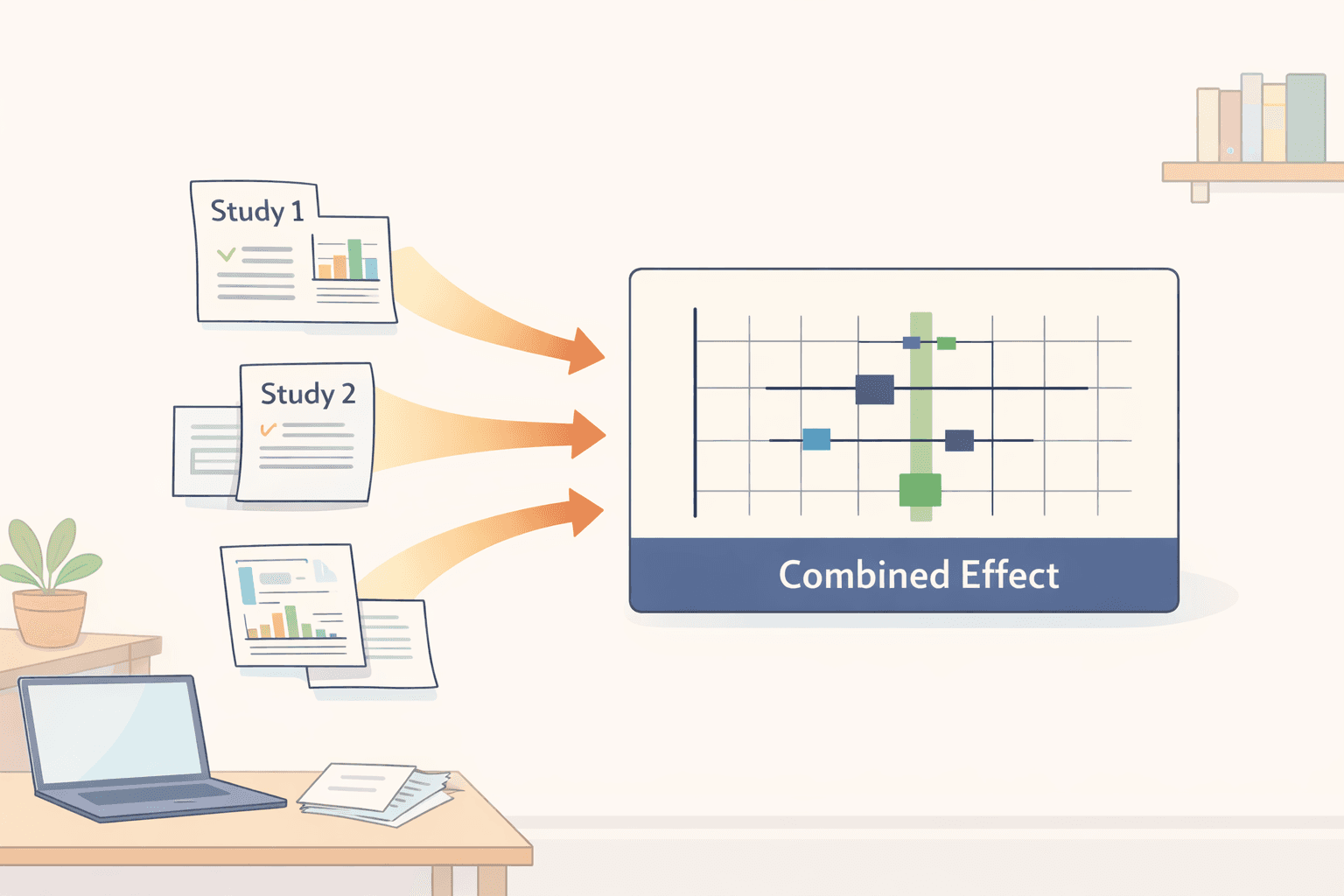
ここから、すべての研究から得られた数値が統合されて1つの結果になります。
まず、データに適した統計的な尺度、すなわち「効果量」を選択します。一般的なものには、オッズ比(「はい/いいえ」のアウトカム用)、リスク比、または標準化平均値差(平均値の比較用)があります。
次に、統計モデルを選択します。すべての研究が単一の真の効果を推定していると仮定する場合は「固定効果モデル」を採用します。より一般的なのは「変量効果モデル(ランダム効果モデル)」です。これは、真の効果が各研究間で多少異なる可能性があるという考え方を許容します。
これらの統計的原則に関する定番の解説については、結果の統合方法と解釈を詳しく説明しているメタ分析の原則と手順を参照してください。
分析において不可欠なのは「異質性」、つまり、各研究結果の間の不一致の度合いを評価することです。I²統計量を用いてこれを定量化します。値が25%未満であれば不一致(異質性)は低いとされ、50%を超えると高いと判断されます。
I²が高い場合は、それぞれの研究が大きく異なる結果を示していることを意味します。この場合でも統合された結果には意味がありますが、解釈は慎重に行い、そのばらつきが生じた理由を説明する必要があります。
ステップ 8: ビジュアル出力の作成と解釈
メタ分析の結果は、通常プロット図を用いて視覚化されます。これは単なる見栄えのためではなく、難解な統計結果を非常に明確で分かりやすい形で読者に伝えるためです。
フォレストプロット(Forest plots) これは最もよく使われるチャートです。フォレストプロットはいくつかの情報を同時に示します。
分析に含まれる個々の研究の効果量と信頼区間を表示します。
それらすべての研究を組み合わせた統合効果量(pooled effect size)を示します。
視覚的なレイアウトにより、どの研究が一致しているか、どれが外れ値か、そして全体的な結果がどの程度正確であるかを一目で把握できます。
ファンネルプロット(Funnel plots) 研究者は、このプロットを使用して「出版バイアス」という特定の問題をチェックします。これは、肯定的または劇的な結果が得られた研究の方が、否定的あるいは一見つまらない結果の研究よりも出版されやすい傾向を指します。
左右対称の「逆漏斗型(逆さのファンネル)」であれば、このバイアスの影響は最小限であると考えられます。
一方、プロットが左右非対称で偏っていたり隙間があったりする場合は、重要なデータが分析から抜け落ちており、最終的な結論が歪んでいる可能性を示す警戒信号となります。
なぜビジュアルが重要なのか 端的に言えば、適切に作成されたチャートは、何段落もある文章での解説を数秒で伝えてくれます。大量の数値を、誰でもすぐに理解し、疑問を投げかけ、信頼できるストーリーへと変えてくれます。
<ProTip title="📊 プロのヒント:" description="フォレストプロットを使って、全体的な調査結果を迅速に伝えましょう" />
ステップ 9: 発展的な分析の実施
メタ分析から得られる基本的な統合結果は有益ですが、それだけでは全容を語りきれないことが多々あります。より明確で詳細な状況を把握するために、高度な分析を実行します。これらの手法は、結果の頑健性をテストし、数値の背景にある「理由」を探るのに役立ちます。
一般的な手法
サブグループ分析: データをいくつかのカテゴリに分解します。例えば、男性を対象とした研究と女性を対象とした研究の結果を比較したり、高用量と低用量での比較などを行います。「異なるタイプの人、あるいは異なる条件下において、効果は変化するか?」という問いに答えることができます。
感度分析: メインの結果がどの程度強固であるかをチェックします。仮に最大の研究を取り除いた場合はどうなるでしょうか?あるいは、バイアスリスクが高い研究を除外した場合はどうなるでしょうか?結論が覆るようであれば実質的な結果は脆いものであり、一貫して変わらないのであれば、その結果に対する自信をより深めることができます。
メタ回帰分析: より統計的なアプローチです。単に研究をグループ分けするのではなく、参加者の平均年齢や発表年などの特定の研究特性が、効果量とどのように量的な相関関係にあるかをモデリングします。
応用例 仮にあなたのメタ分析により、新しい個別指導プログラムが学生にとって有効であることが分かったとします。しかし、サブグループ分析を行うことで、それが高校生には役立つものの、中学生には効果がないことが明らかになるかもしれません。
また、感度分析を行うことで、その結果が実質的に1つのずさんな設計の研究に全面的に依存していることが明らかになる可能性もあります。メタ回帰を行えば、プログラムの有効性が、開始されてからの経過年数とともに毎年少しずつ低下していることが判明するかもしれません。
こうした高度な分析は単にデータをまとめるだけでなく、データに「問いかける」作業です。研究結果がなぜばらつくのかを説明し、どのような状況において、誰に対して最もエビデンスが有力であるかを正確に突き止めることができます。
ステップ 10: 結果の明確な報告
どんなに優れたメタ分析を行っても、レポートの書き方が悪ければ台無しになってしまいます。明確で構造化された報告こそが、あなたの成果を他の科学者にとって信頼でき、有用で、価値のあるものにするのです。
PRISMA声明に従う 現在、多くの研究者がPRISMAフレームワークを採用しています。これは、レポートに含めるべき項目のチェックリストです。もし報告前にレビュータイプの違いを整理したい場合は、メタ分析 vs 系統的レビューを比較したこちらのガイドが、構成や用語づかいを正確にするのに役立ちます。
フローダイアグラム: 数千の文献検索から始まり、最終的に数件の研究を選定するまでの過程を示すビジュアルマップ。全ての判断基準を記録します。
研究特性一覧表: 含まれる各研究のデザイン、参加者、主要な結果を体系的にまとめた表。
統計結果: 統合効果量、信頼区間、異質性検定など、分析から得られたすべての数値。
限界点(リミテーション): 出版バイアスの可能性や、元データとなる研究の質の低さなど、自身のレビューの弱点に関する客観的な議論。
PRISMAを使用することは、単なる形式的な手続きではありません。自分の作業プロセスを示すことで、他の人が正しくそれを評価し、さらには再現することを可能にします。
執筆のコツ
簡潔に記述する。要点を素早く伝える。
他の誰かが再現できるように、方法論(メソッド)セクションを詳しく説明する。
データが実際に示している事実のみに忠実であること。結論を誇張したり、エビデンスを超えた憶測を控えたりする。
よくある課題とその対策
正直なところ、メタ分析を行うのは簡単ではありません。技術的で時間のかかるプロセスであり、特に初心者のうちは、数々の障壁に直面するのが一般的です。
よくある課題
データ欠損への対応: よくある問題です。著者が求める正確な数値を報告していないことがあります。著者に直接連絡を取るか、推定値を用いるか、あるいはその研究そのものを除外する決断を迫られます。
異質性のコントロール: 対象とする研究が大幅に異なる結果を示している場合、それらを統合することに無理が生じる可能性があります。そのばらつきが許容範囲内であるかどうか、または分析全体を無効にしてしまう要因なのかを見極める必要があります。
統計ソフトの習得: 一般的な表計算ソフト(Excelなど)だけでは対応できません。専用の専門ツールが必要になり、その習得のハードルは高めです。
実践的な解決策
適切なツールを使う: R(metafor や meta パッケージなど)やRevManなどのソフトウェアは、この目的のために構築されています。複雑な計算もスムーズに処理できます。
小さく始める: 初めのうちは、一気に50もの研究を統合しようとしないことです。焦点を絞った問いを立て、5〜10本の論文程度の扱いやすい規模で練習しましょう。
サポートを求める: 早い段階で専門の統計家や経験豊富な同僚に相談することです。これにより、数ヶ月に及ぶ無駄な試行錯誤を避けることができます。
現実に即した認識 適切な系統的レビューとメタ分析は、週末だけで完了するようなプロジェクトではありません。それ自体が一大研究プロジェクトです。
多くの研究チームが、これを十分な質で仕上げるまでに3ヶ月から1年近い期間を要したと報告しています。このプロセスには、忍耐強さ、入念な整理、そして学習を継続する姿勢が求められます。
<ProTip title="⚠️ プロのヒント:" description="統計分析を急いではいけません。スピードよりも正確性の方が重要です" />
メタ分析を実施するためのツール
どのソフトウェアを選択するかによって、プロセスが驚くほどスムーズになることも、逆に困難になることもあります。適切なツールを使用すれば、複雑な統計計算を任せ、研究の中身に集中することができます。スクリーニングや抽出の過程で、大量のPDFライブラリや引用一覧を管理する場合は、研究者向けZotero・Mendeley連携方法が情報の整理に役立ちます。
人気のソフトウェア
R (metafor や meta パッケージ)
RevMan (Cochrane開発)
Stata
Comprehensive Meta-Analysis (CMA)
簡単な比較
ツール | 費用 | 最適な対象 |
R | 無料 | 上級者、フルカスタマイズを望むユーザー |
RevMan | 無料 | 初心者、コクランスタイルのレビュー |
Stata | 有料(ライセンス) | プロの研究チーム |
CMA | 有料(ライセンス) | クリック操作(GUI)を好む研究者 |
どれも即座に使いこなせるほど簡単ではありません。それぞれに学習が必要となります。初めて取り組む場合は、より高度なオプションへと挑戦する前に、実績を積むためにRevManのようなシンプルでガイド付きのツールから始めるのが最適なアプローチです。
メタ分析を成功させるために
メタ分析を成功させるには、構造化された計画、入念なデータ管理、そして透明な報告プロセスが必要です。それぞれのステップが次のステップの土台となり、信頼できる研究が形成されます。
<CTA title="研究をクリアな文章に変換する" description="複雑なメタ分析のワークフローを構造化された論文へ簡単に整理します" buttonLabel="Jenniを無料で試す" link="https://app.jenni.ai/register" />
ステップバイステップのアプローチを忠実になぞることで、正確で価値のある結果を生み出すことができます。Jenniなどのツールは、アイデアの整理、タスクの管理、結果のクリアな伝達をサポートすることで、一連のプロセスを支援します。