







Del borrador a la retroalimentación de revisión por pares en tres pasos
Sube tu borrador
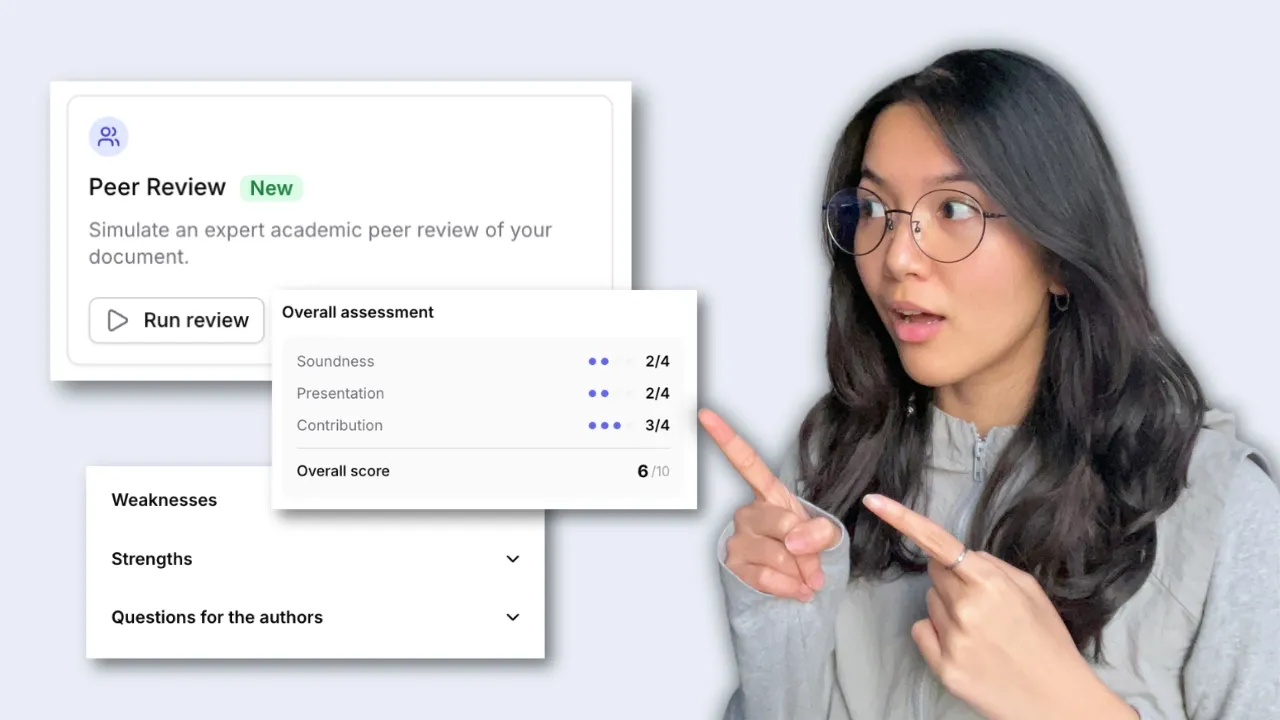
Realizar revisión por pares
Jenni analiza tu manuscrito frente a los criterios estándar de revisión por pares, evalúa las áreas clave y destaca mejoras concretas directamente en tu borrador.
Resuelve, vuelve a ejecutar, repite
Los comentarios se insertan directamente en tu manuscrito, vinculados exactamente a los fragmentos que necesitas mejorar. Resuelve cada observación y observa cómo se eleva la calidad de tu trabajo.
Descubre la revisión por pares en acción
Mira cómo Jenni lee un manuscrito real, lo evalúa según la rúbrica y deja comentarios en cada sección que necesita mejoras.
Creado para el rigor académico
La mayoría de las herramientas de IA te ofrecen comentarios genéricos sobre tu escritura. Peer Review evalúa tu manuscrito como lo haría un revisor.

Lee el manuscrito completo
Peer Review lee tu borrador completo de principio a fin, captando cada afirmación, cada nota metodológica y cada transición, para que la retroalimentación refleje todo el documento.

Los mismos criterios que usan los revisores
Peer Review completa el mismo formulario de revisión que utilizan las principales revistas, con puntuaciones sobre la solidez, la contribución y la presentación, además de comentarios por escrito.

Comentarios vinculados a pasajes
Jenni vincula cada comentario a una oración específica, con una explicación y una sugerencia de corrección. Sabes qué cambiar y dónde, no solo que algo no está bien.
Tu revisión completa de citas antes de enviar
Peer Review es una de las cuatro herramientas de revisión que detectan problemas antes que los revisores. Úsalas en conjunto para realizar una revisión completa antes de enviar tu trabajo.
Peer review8 / 10
Manuscript scored against a peer-review rubric with reviewer comments on each section.
Soundness
3/4
Presentation
4/4
Contribution
3/4
Results
Strengths
Weaknesses
Claim confidence10 issues
The claim confidence analysis addressed issues of redundant, weak, or missing citations, alongside instances of contradiction in citation arguments.
Misrepresented
Contradicted
3Unsupported
4Weakly supported
2Overstated
Unverifiable
Outdated
2Self-citation heavy
Predatory source
Citation mismatch
1Proofread18 edits
Whilst generally sound, the text contains some areas for improvement to comply with academic best practices.
Word choice
AllThe majority of participants reported improved outcomes.
Formality
Yang (2024) found a negative correlation which was interesting..
Grammar
These results indicate that early intervention be effective. appears to be effective.
Transitions
Also, In addition, Jones (2022) found similar results.
Overgeneralized
AllThe majority of participants reported improved outcomes.
The results provesuggest that X has an effect on Y.Tone of voice22 notes
Suggestions across vocabulary, syntax, punctuation, tone and flow to keep a consistent academic voice.
All Suggestions
22Vocabulary
6Syntax
5Punctuation
4Tone
3Flow
4Revisión por pares
Inspira Confianza
Revisar
Tono de voz


Nuestros usuarios han publicado artículos en más de 100 revistas
Investigación real, publicada en revistas como IEEE, Springer y Elsevier: planificada y redactada con Jenni.
