







Vom Entwurf zum Feedback aus der Peer-Review in drei Schritten
Legen Sie Ihren Entwurf hier ab
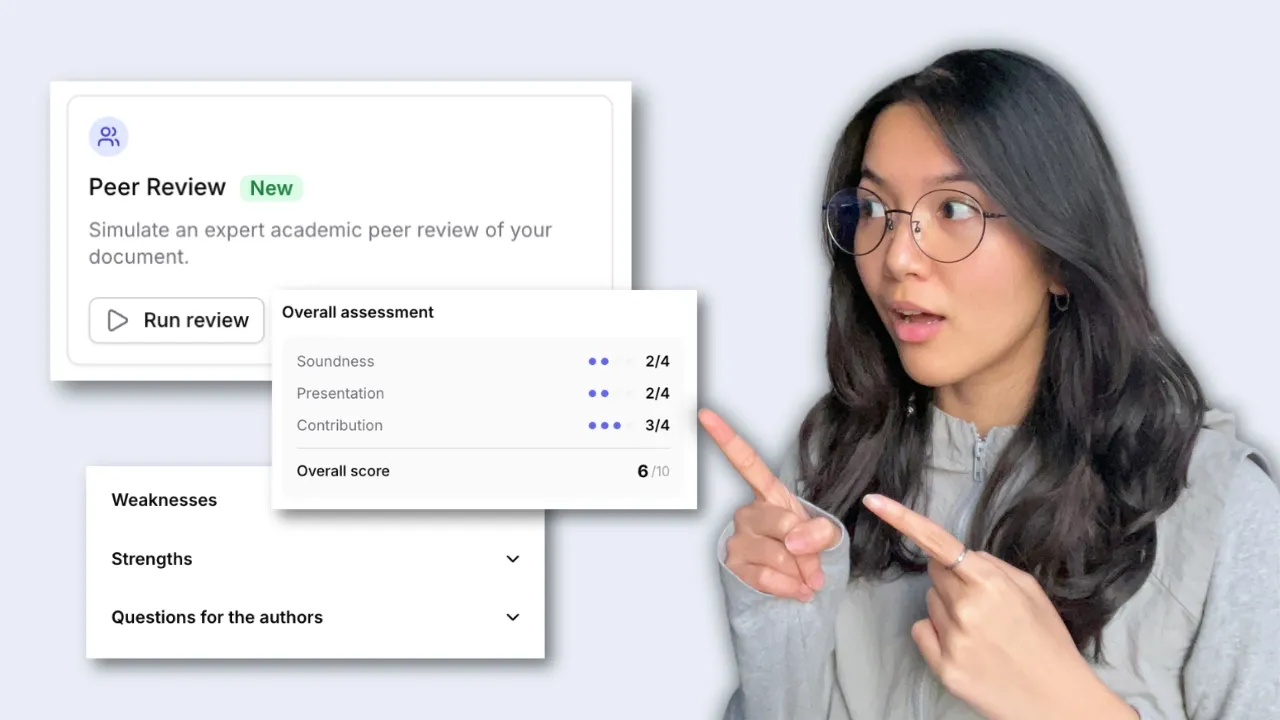
Peer-Review durchführen
Jenni prüft Ihr Manuskript anhand standardmäßiger Peer-Review-Kriterien, bewertet Schlüsselbereiche und markiert umsetzbare Verbesserungen direkt in Ihrem Entwurf.
Beheben, erneut ausführen, wiederholen
Kommentare landen direkt in Ihrem Manuskript, verknüpft mit den exakten Stellen, die überarbeitet werden müssen. Gehen Sie auf jeden Kritikpunkt ein und sehen Sie zu, wie sich Ihre Bewertung verbessert.
Peer Review in Aktion sehen
Sehen Sie, wie Jenni ein echtes Manuskript liest, es anhand des Bewertungsschemas bewertet und Kommentare dort hinterlässt, wo jeder Abschnitt überarbeitet werden muss.
Für akademischen Anspruch entwickelt
Die meisten KI-Tools geben Ihnen generisches Feedback zu Ihren Texten. Peer Review bewertet Ihr Manuskript so, wie es ein Gutachter tun würde.

Liest das vollständige Manuskript
Peer Review liest Ihren vollständigen Entwurf von Anfang bis Ende und erfasst jede Behauptung, jede Methodennotiz und jeden Übergang, sodass das Feedback das gesamte Dokument widerspiegelt.

Dieselben Kriterien, die Gutachter verwenden
Peer Review verwendet dasselbe Begutachtungsformular wie führende Fachzeitschriften, mit Bewertungen für Solidität, Beitrag und Darstellung sowie schriftlichem Feedback.

Kommentare zu Passagen
Jenni verknüpft jeden Kommentar mit einem bestimmten Satz, mit einer Begründung und einem vorgeschlagenen Fix. Du weißt genau, was du ändern musst und wo – nicht nur, dass etwas nicht stimmt.
Ihre vollständige Zitierprüfung vor der Einreichung
Peer Review ist eines von vier Review-Tools, die Probleme finden, bevor Prüfer es tun. Führen Sie sie zusammen aus, um eine vollständige Prüfung vor der Einreichung zu erhalten.
Peer review8 / 10
Manuscript scored against a peer-review rubric with reviewer comments on each section.
Soundness
3/4
Presentation
4/4
Contribution
3/4
Results
Strengths
Weaknesses
Claim confidence10 issues
The claim confidence analysis addressed issues of redundant, weak, or missing citations, alongside instances of contradiction in citation arguments.
Misrepresented
Contradicted
3Unsupported
4Weakly supported
2Overstated
Unverifiable
Outdated
2Self-citation heavy
Predatory source
Citation mismatch
1Proofread18 edits
Whilst generally sound, the text contains some areas for improvement to comply with academic best practices.
Word choice
AllThe majority of participants reported improved outcomes.
Formality
Yang (2024) found a negative correlation which was interesting..
Grammar
These results indicate that early intervention be effective. appears to be effective.
Transitions
Also, In addition, Jones (2022) found similar results.
Overgeneralized
AllThe majority of participants reported improved outcomes.
The results provesuggest that X has an effect on Y.Tone of voice22 notes
Suggestions across vocabulary, syntax, punctuation, tone and flow to keep a consistent academic voice.
All Suggestions
22Vocabulary
6Syntax
5Punctuation
4Tone
3Flow
4Peer-Review
Anspruch Vertrauen
Korrekturlesen
Tonfall


Unsere Nutzer haben Artikel in über 100 Fachzeitschriften veröffentlicht
Echte Forschungsarbeiten, veröffentlicht in Fachzeitschriften wie IEEE, Springer und Elsevier – geplant und verfasst in Jenni.
