Por
Nathan Auyeung
—
Exemplos de Desenho Quase-Experimental: Tipos e Casos de Uso Reais

Nathan Auyeung
Contabilista Sênior na EY
Formado com um Bacharelado em Contabilidade, completou um Diploma de Pós-Graduação em Contabilidade

Os designs quase-experimentais ajudam os investigadores a estudar a causa e o efeito quando a atribuição aleatória não é possível. Em vez de dependerem de grupos aleatórios controlados, estes estudos utilizam cenários do mundo real, tais como escolas, clínicas, bairros ou regiões.
Isso torna-os especialmente úteis na educação, na saúde e nas políticas públicas, onde os investigadores precisam frequentemente de respostas, mas não conseguem controlar totalmente quem recebe uma intervenção.
Neste guia, analisaremos os exemplos quase-experimentais mais importantes, explicaremos o que faz com que cada design funcione e mostraremos como escolher e aplicar a abordagem correta no seu próprio estudo com clareza e confiança.
<CTA title="Desenhe uma Pesquisa Melhor Mais Rápido" description="Gere designs quase-experimentais estruturados com clareza e lógica forte em minutos." buttonLabel="Experimente o Jenni Grátis" link="https://app.jenni.ai/register" />
O Que É um Design de Pesquisa Quase-Experimental?
Um design de pesquisa quase-experimental examina causa e efeito sem atribuição aleatória.
Em vez de criar grupos aleatórios, utiliza grupos formados naturalmente que já existem em cenários reais, o que torna a abordagem mais realista para a pesquisa aplicada. Os investigadores trabalham habitualmente com salas de aula, hospitais ou comunidades já existentes.
Conforme explicado em quasi experimental design, os quase-experimentos são amplamente utilizados em estudos aplicados porque oferecem um equilíbrio prático entre a viabilidade e uma perspicácia causal significativa.
Ao contrário de um experimento verdadeiro, os participantes não são atribuídos aleatoriamente às condições. Isto pode tornar mais difícil excluir explicações alternativas, uma vez que os grupos podem diferir uns dos outros antes de a intervenção começar.
Como resultado, a validade interna pode ser um desafio nos designs quase-experimentais. Mesmo com estas limitações, os métodos quase-experimentais continuam a ser essenciais em disciplinas como a sociologia, a psicologia e a economia.
Variável independente: a intervenção ou tratamento
Variável dependente: o resultado medido
Grupo de controlo: o grupo de comparação que não recebe o tratamento
Grupo de tratamento: o grupo que recebe a intervenção
<ProTip title="💡 Dica Pro:" description="Defina sempre as variáveis claramente antes de selecionar um design quase-experimental." />
Tipos Principais de Exemplos de Design Quase-Experimental
Aqui estão os principais tipos que verá na prática. As explicações incluem exemplos simples e onde os utilizaria de facto.
Design de grupo de controlo não equivalente
Dois grupos são comparados, mas não foram atribuídos aleatoriamente. Já existiam previamente.
Exemplo: Uma turma de uma escola recebe um novo programa de matemática. Outra turma utiliza o método antigo. No final do período, comparam-se as notas dos testes.
Onde é utilizado: Isto está em todo o lado na pesquisa educacional. Como os grupos não foram criados iguais à partida, os investigadores têm de utilizar a estatística (como a ANCOVA) para tentar dar conta das diferenças iniciais. O grande desafio é lidar com variáveis que não se tiveram em conta.
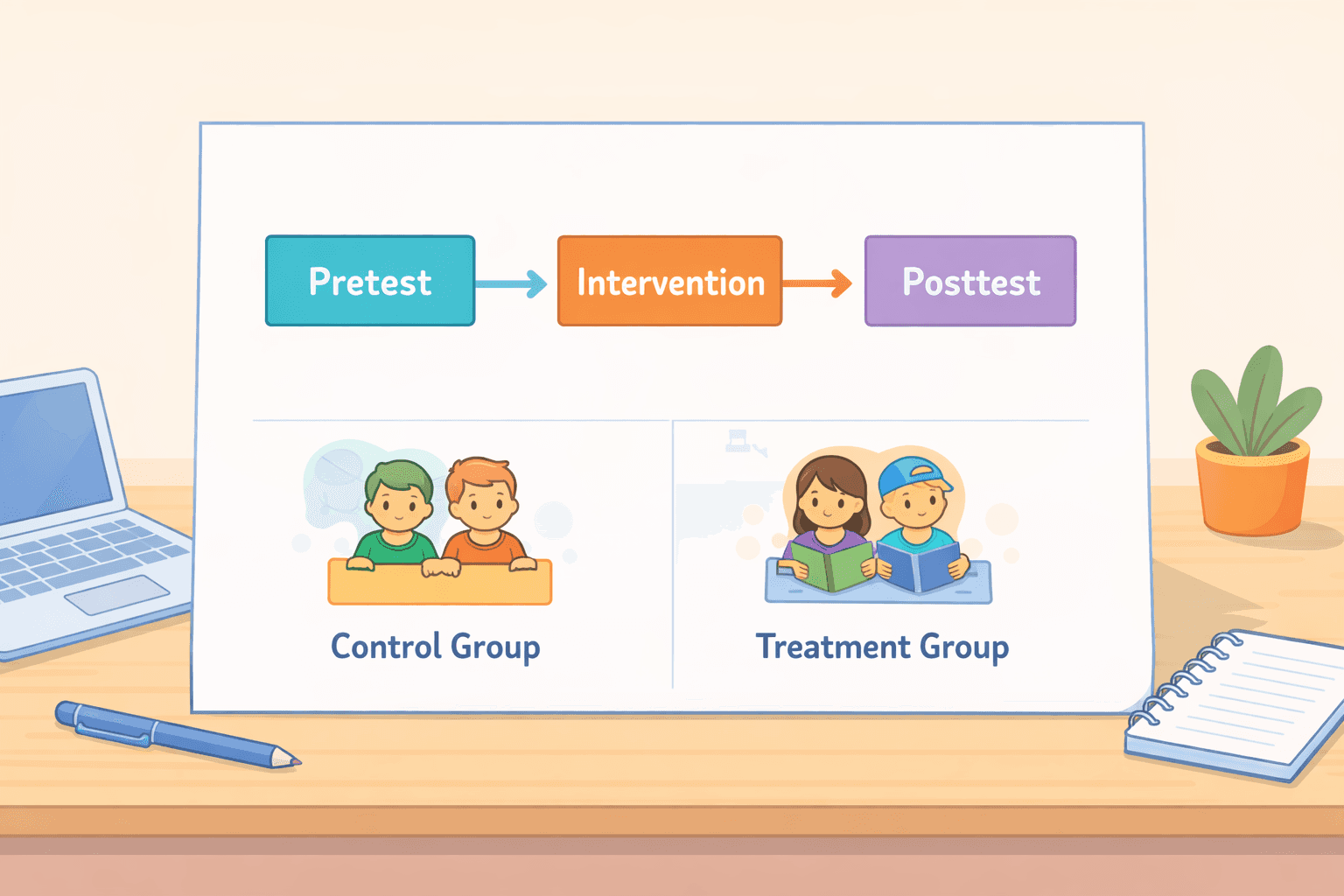
Design pré-teste/pós-teste de grupo único
Mede-se um único grupo, introduz-se algo e, em seguida, mede-se novamente. Não existe um grupo de controlo separado.
Exemplo: Uma fábrica regista quantos acidentes acontecem ao longo de seis meses. Depois, realizam um programa de formação em segurança. Posteriormente, acompanham os acidentes durante mais seis meses para ver se o número diminuiu.
Por que razão é fraco: A diminuição de acidentes pode dever-se à formação. Ou pode dever-se a outra coisa que aconteceu ao mesmo tempo, como uma redução sazonal na produção. É difícil ter a certeza do que causou a alteração.
A compensação: É muito fácil e barato de fazer, razão pela qual é comum em estudos de empresas e locais de trabalho. Mas dá-lhe a evidência mais fraca de causa e efeito.
Pré-teste/pós-teste com um grupo de controlo não equivalente
Esta é uma versão mais forte. Tem dois grupos existentes e mede ambos antes e depois de introduzir uma alteração a apenas um dos grupos.
Exemplo: Uma clínica inicia um novo programa para ajudar as pessoas a deixarem de fumar. Outra clínica semelhante não o faz. Questiona os fumadores de ambas as clínicas sobre os seus hábitos. Após um ano de execução do programa na primeira clínica, questiona todos novamente.
Por que razão é melhor: Se a clínica com o programa mostrar uma diminuição muito maior no tabagismo do que a outra clínica, pode estar mais confiante de que o programa realmente funcionou. Ajuda a excluir a possibilidade de que algum fator externo (como uma nova campanha de saúde pública) tenha afetado todos ao mesmo tempo.
Eis como estes três primeiros designs se comparam:
Tipo de Design | Grupo de Controlo? | Pré-teste? | Força da Evidência |
Pré-teste/pós-teste de grupo único | Não | Sim | Baixa |
Grupo de controlo não equivalente | Sim | Opcional | Média |
Pré-teste/pós-teste com controlo | Sim | Sim | Mais Alta |
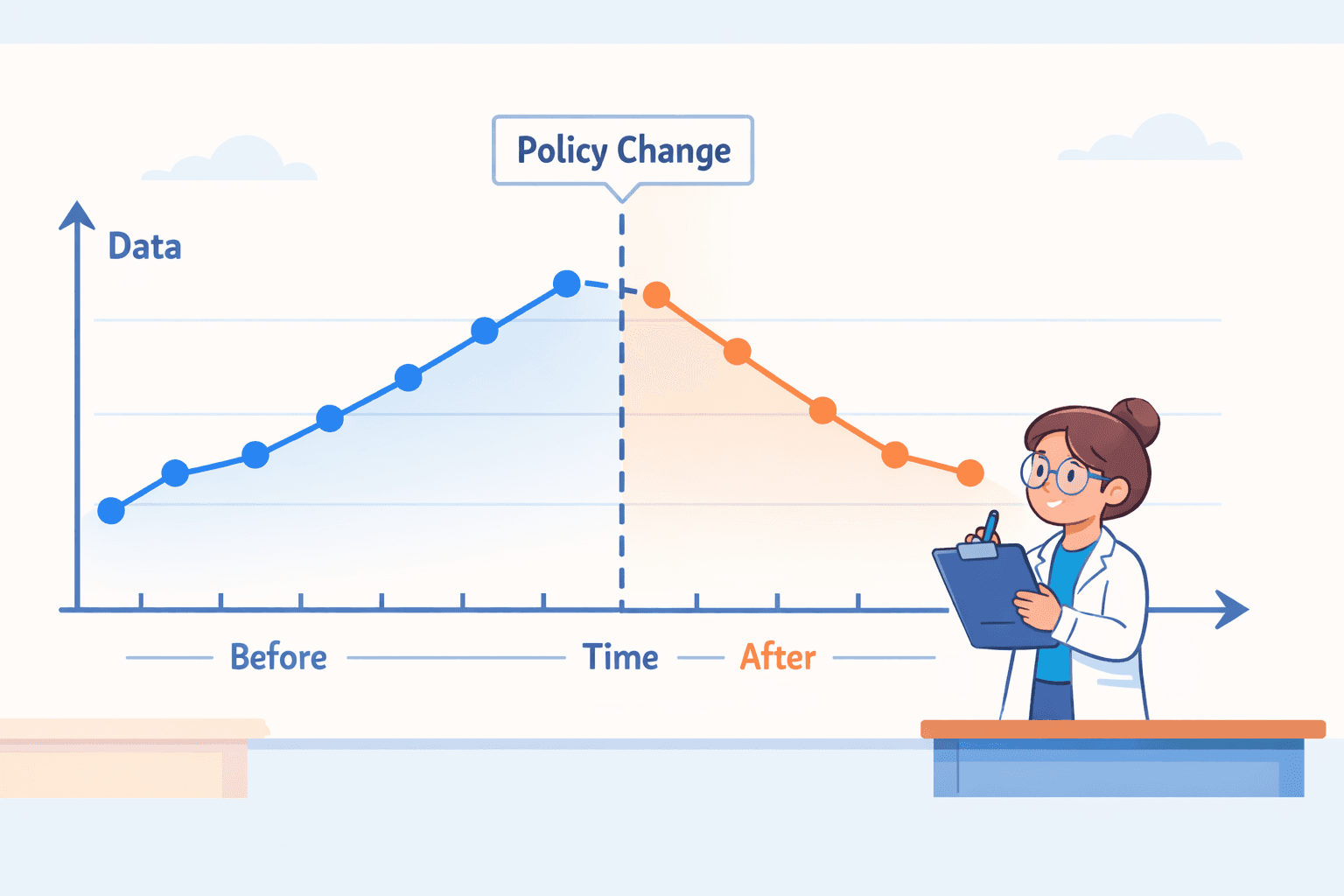
Design de séries temporais interrompidas
Em vez de apenas uma medição "antes" e uma "depois", recolhe dados em muitos pontos ao longo de um período prolongado. Procura uma mudança na tendência após um evento específico.
Exemplo: Um país aprova uma lei que taxa as bebidas açucaradas. Os investigadores analisam os dados de vendas de refrigerantes a nível nacional, mês a mês, durante anos antes da taxa e anos depois. Estão à procura de ver se a tendência a longo prazo das vendas cai claramente ou se altera o seu padrão exatamente quando a taxa começou.
Por que razão é útil: É poderoso para avaliar políticas e leis. Ver uma alteração num padrão a longo prazo é mais convincente do que uma alteração entre dois pontos únicos no tempo. Uma discussão aplicada detalhada pode ser encontrada em interrupted time series design in real world studies, que mostra como os designs baseados no tempo são utilizados na pesquisa de saúde no mundo real.
<ProTip title="📊 Lembrete:" description="Utilize pelo menos 12 pontos temporais antes e depois para uma análise forte de séries temporais interrompidas." />
Design de descontinuidade de regressão
As pessoas são atribuídas a um grupo de tratamento com base no facto de estarem acima ou abaixo de um ponto de corte específico numa escala.
Exemplo: Uma universidade concede bolsas de tutoria a estudantes cujo rendimento familiar seja inferior a $50.000. Os investigadores comparam então as taxas de graduação dos estudantes que quase se qualificaram (por exemplo, rendimento de $49.500) com os que quase falharam (por exemplo, rendimento de $50.500).
A lógica: A ideia é que estes dois grupos de estudantes são virtualmente idênticos em todos os aspetos, exceto por essa pequena diferença de rendimento e pela bolsa que receberam. Qualquer grande diferença nos seus resultados pode ser associada com maior segurança à bolsa. Os economistas e os analistas de políticas adoram este design pela sua lógica inteligente.
Designs de emparelhamento por pontuação de propensão
Como não se pode fazer a aleatorização, tenta-se simulá-la com estatística. Encontram-se indivíduos no grupo de tratamento e "emparelham-se" com indivíduos quase idênticos de um grupo sem tratamento.
Exemplo: Está a estudar cursos universitários online versus presenciais. Pega em cada aluno online e encontra um aluno presencial com a mesma média do ensino secundário, idade e curso. Em seguida, compara as notas destes pares emparelhados.
O senão: Apenas se pode emparelhar pessoas com base em coisas que se podem medir e para as quais se tem dados. Não pode dar conta de diferenças ocultas, como o nível de motivação de um aluno ou o seu acesso a um local silencioso para estudar. Reduz o viés, mas não o elimina.
<ProTip title="⚙️ Dica Pro:" description="Verifique sempre o equilíbrio após o emparelhamento para validar o seu design quase-experimental." />
Exemplos Reais de Design Quase-Experimental por Domínio
Vê-se estes métodos em todo o lado. Eis como se parecem na prática em algumas áreas fundamentais.
Educação
As escolas não costumam baralhar as crianças aleatoriamente para uma experiência. Por isso, trabalham com os grupos que têm.
Como se parece: Um distrito escolar decide experimentar um novo programa de tutoria online. Dão-no a todos os alunos da Lincoln High School. Entretanto, os alunos da Jefferson High School continuam a utilizar o antigo sistema de sala de estudo. No final do semestre, os investigadores comparam as notas dos exames finais de ambas as escolas.
Por que razão é utilizado: É uma forma standard e prática de testar novas ferramentas ou programas de ensino quando a aleatorização real não é uma opção.
Saúde
Os hospitais e as clínicas utilizam grupos de doentes existentes para estudar novos procedimentos ou sistemas.
Como se parece: Um hospital instala um novo sistema digital para os enfermeiros monitorizarem os sinais vitais dos doentes. Analisam o tempo médio de recuperação dos doentes admitidos nos seis meses anteriores ao sistema entrar em funcionamento e comparam-no com o tempo de recuperação dos doentes nos seis meses seguintes.
Por que razão é utilizado: Não se pode atribuir aleatoriamente alguns doentes para receberem piores cuidados. Esta abordagem permite que os investigadores de saúde estudem melhorias no mundo real de uma forma controlada.
Políticas Públicas
Quando uma nova lei ou imposto é introduzido, afeta toda a gente. Os investigadores estudam os efeitos analisando dados ao longo do tempo.
Como se parece: Um estado aumenta a idade legal para comprar tabaco de 18 para 21 anos. Os responsáveis de saúde pública acompanham então as taxas de tabagismo a nível estadual entre os adolescentes durante vários anos antes e depois da alteração da lei, procurando uma queda na linha de tendência.
Por que razão é utilizado: Este é frequentemente um design de séries temporais interrompidas. É a principal forma de descobrir se uma política em grande escala causou de facto a mudança que todos esperavam.
Negócios e Marketing
As empresas testam novas ideias num subconjunto de clientes antes de um lançamento completo, muitas vezes porque um teste A/B real não é possível.
Como se parece: Uma aplicação de redes sociais desenvolve uma nova funcionalidade de vídeo. Lançam-na primeiro para todos os utilizadores no Canadá. Durante três meses, acompanham a frequência com que os utilizadores canadianos assistem a vídeos em comparação com utilizadores de mercados semelhantes, como o Reino Unido e a Austrália, que ainda não têm a funcionalidade.
Por que razão é utilizado: Os analistas, mesmo em fóruns como o Reddit, chamam a isto um "lançamento faseado". Permite que uma empresa veja a utilização no mundo real e detete problemas antes de um lançamento global, enquanto continua a recolher dados comparativos.
Este tipo de estudo situa-se frequentemente entre a perspicácia qualitativa e a medição quantitativa. Se não tiver a certeza de como estas abordagens diferem, qualitative vs quantitative research explica como cada método contribui para as decisões de design de pesquisa.
Vantagens e Desvantagens do Design Quase-Experimental
Saber no que estes métodos são bons e onde falham é fundamental para julgar os estudos que os utilizam.
Vantagens
A maior força é que lhe permitem estudar as coisas quando uma experiência real não é possível ou ética.
Utilização no mundo real: Pode pesquisar programas, políticas e tratamentos tal como acontecem de facto em escolas, hospitais ou cidades. Não está a criar um cenário de laboratório artificial.
Praticidade ética: Muitas vezes, não se pode negar aleatoriamente a alguém um tratamento potencialmente útil. Os National Institutes of Health apontam que muitos estudos clínicos têm de utilizar designs não aleatorizados exatamente por esta razão.
Eficiência: Os investigadores podem frequentemente utilizar dados que já existem, como registos escolares ou de admissão hospitalar. Isto torna os estudos mais rápidos e menos dispendiosos de executar.
Escala: Estes designs podem ser aplicados a grandes grupos, até mesmo populações inteiras, o que é necessário para avaliar coisas como novas leis ou campanhas de saúde pública.
Desvantagens
A maior compensação é uma alegação mais fraca sobre causa e efeito. Não pode ter tanta certeza de que o tratamento que está a estudar é a verdadeira razão para qualquer alteração.
O problema central: Sem atribuição aleatória, os grupos que está a comparar podem ter sido diferentes desde o início. Talvez os alunos no novo programa de matemática tivessem pais com maior capacidade de apoio. Talvez os doentes que receberam uma nova terapia fossem geralmente mais saudáveis. Estas diferenças pré-existentes podem distorcer os seus resultados.
Variáveis de confusão: Estes são os fatores não medidos que podem ser de facto responsáveis pelo resultado. São a ameaça constante neste tipo de pesquisa.
Viés de seleção: A forma como as pessoas acabam num grupo ou noutro não é aleatória. As pessoas que escolhem aderir a um novo programa podem estar mais motivadas do que as que não o fazem, o que por si só poderia levar a melhores resultados.
Incerteza: No fim de contas, fica com uma correlação forte, semelhante à que se vê na pesquisa correlacional, mas não uma prova definitiva de causalidade. A evidência é sugestiva, não à prova de bala.
Uma explicação mais profunda destes desafios e da forma como os investigadores os gerem é discutida em quasi experimental design validity and causal inference, que explora questões de inferência causal e validade em designs quase-experimentais.
<ProTip title="⚠️ Nota:" description="Relate sempre as limitações claramente para reforçar a credibilidade da pesquisa." />
Como Desenhar um Estudo Quase-Experimental Passo a Passo
Se precisar de executar um destes estudos, eis um caminho simples a seguir.
1. Defina a sua questão Comece com uma questão clara de causa e efeito. Seja específico.
Fraco: "O programa funciona?"
Melhor: "Os alunos do ensino secundário que completam o novo programa de tutoria de pares mostram um maior aumento nas notas dos exames finais de álgebra do que os que não o fazem?"
2. Encontre os seus grupos Não criará os grupos aleatoriamente. Utilizará os que já existem.
Grupo de tratamento: As pessoas, salas de aula ou regiões que receberão a intervenção (por exemplo, as três filiais da empresa que recebem o novo software).
Grupo de controlo/comparação: Os grupos que continuarão como habitualmente (por exemplo, as duas filiais que mantêm o sistema antigo). O seu objetivo é tornar estes grupos tão semelhantes quanto possível desde o início.
3. Escolha o seu design A sua escolha depende inteiramente do que for prático para a sua situação.
Se apenas tiver acesso a um grupo, utilizará um design de pré-teste/pós-teste de grupo único.
Se tiver dois grupos existentes e puder medi-los antes e depois, utilize um pré-teste/pós-teste com um grupo de controlo não equivalente.
Se estiver a estudar uma alteração de política e tiver dados ao longo de muitos anos, um design de séries temporais interrompidas é a sua melhor aposta.
Se o tratamento for decidido por um ponto de corte estrito (como uma nota de teste ou nível de rendimento), um design de descontinuidade de regressão é a opção mais rigorosa.
4. Dê conta de outras variáveis Este é o passo analítico mais crítico. Como não fez a aleatorização, deve tentar controlar outros fatores estatisticamente e utilizar medidas que sejam o mais fiáveis possível.
Emparelhamento: Emparelhe cada pessoa no grupo de tratamento com alguém no grupo de controlo que tenha características semelhantes (idade, nota de teste anterior, etc.).
Análise de regressão: Utilize isto para isolar o efeito do seu tratamento enquanto mantém matematicamente constantes outras variáveis.
Diferença-em-diferenças: Compare a alteração no grupo de tratamento com a alteração no grupo de controlo. Isto ajuda a anular tendências que afetaram ambos os grupos.
Se ainda estiver a decidir como estes métodos se enquadram na sua abordagem de pesquisa mais ampla, os research paradigms podem ajudar a clarificar como diferentes designs se alinham com os objetivos de pesquisa.
5. Analise e relate com cautela Interprete os seus números com cuidado.
Não afirme que "provou" que a intervenção causou a alteração. Diga que a evidência "sugere" ou "apoia" uma ligação causal.
Seja transparente sobre as limitações do estudo. Liste explicitamente as outras variáveis que não pôde controlar e que podem ter influenciado os resultados. Esta honestidade é o que torna a pesquisa credível.
Ao relatar descobertas, a clareza no estilo de citação também importa para a credibilidade. Se estiver a formatar a escrita académica, et-al example apa fornece orientações sobre a utilização adequada de citações em artigos de pesquisa.
<ProTip title="🧠 Dica Pro:" description="Utilize a diferença em diferenças para controlar tendências temporais em quase-experimentos." />
Considerações Finais sobre Design Quase-Experimental
Provavelmente já sentiu como é difícil provar causa e efeito quando não se pode controlar tudo, e os resultados podem parecer incertos ou fáceis de questionar. É frustrante. Estes designs ajudam-no a trabalhar com condições reais, mantendo a capacidade de obter respostas úteis, mesmo quando as configurações perfeitas não são possíveis.
<CTA title="Transforme a sua Ideia de Pesquisa num Design Claro" description="Planeie e estruture estudos quase-experimentais com clareza e confiança utilizando o suporte orientado de IA." buttonLabel="Experimente o Jenni Grátis" link="https://app.jenni.ai/register" />
Em vez de pensar demasiado em cada limitação, concentre-se em construir uma estrutura clara e em explicar bem as suas escolhas. Ferramentas como o Jenni podem ajudá-lo a organizar as suas ideias mais rapidamente e a manter a sua escrita afiada, para que passe menos tempo bloqueado e mais tempo a fazer avançar a sua pesquisa.