







Taslaktan hakem değerlendirmesine sadece üç adımda
Taslağını buraya ekle
Akademik Değerlendirmeyi Başlat
Jenni, taslağınızı standart hakem değerlendirmesi kriterlerine göre inceler, kritik alanları puanlar ve doğrudan metin üzerinde uygulayabileceğiniz iyileştirme önerilerini gösterir.
Soruları çözün, yeniden çalıştırın, başarıyı tekrarlayın
Yorumlar, doğrudan metninizin üzerinde, tam da düzeltilmesi gereken satırlarda görünür. Her bir öneriyi uygulayın ve yazım kalitenizin nasıl yükseldiğini kendi gözlerinizle görün.
Akran Değerlendirmesinin nasıl çalıştığını görün
Jenni’nin gerçek bir makaleyi nasıl okuduğunu, rubriğe göre puanladığını ve her bölümde geliştirilmesi gereken yerlere yorum bıraktığını görün.
Akademik başarı için tasarlandı
Çoğu yapay zeka aracı size sıradan yazım geri bildirimleri verir. Akran Değerlendirmesi ise çalışmanızı tıpkı gerçek bir hakem gibi titizlikle analiz eder.

Taslağınızın tamamını baştan sona okur
Peer Review, taslağınızın tamamını baştan sona okuyarak her iddiayı, her yöntem notunu ve her geçişi yakalar; böylece geri bildirim tüm belgeyi yansıtır.

Hakemlerin kullandığı aynı ölçütler
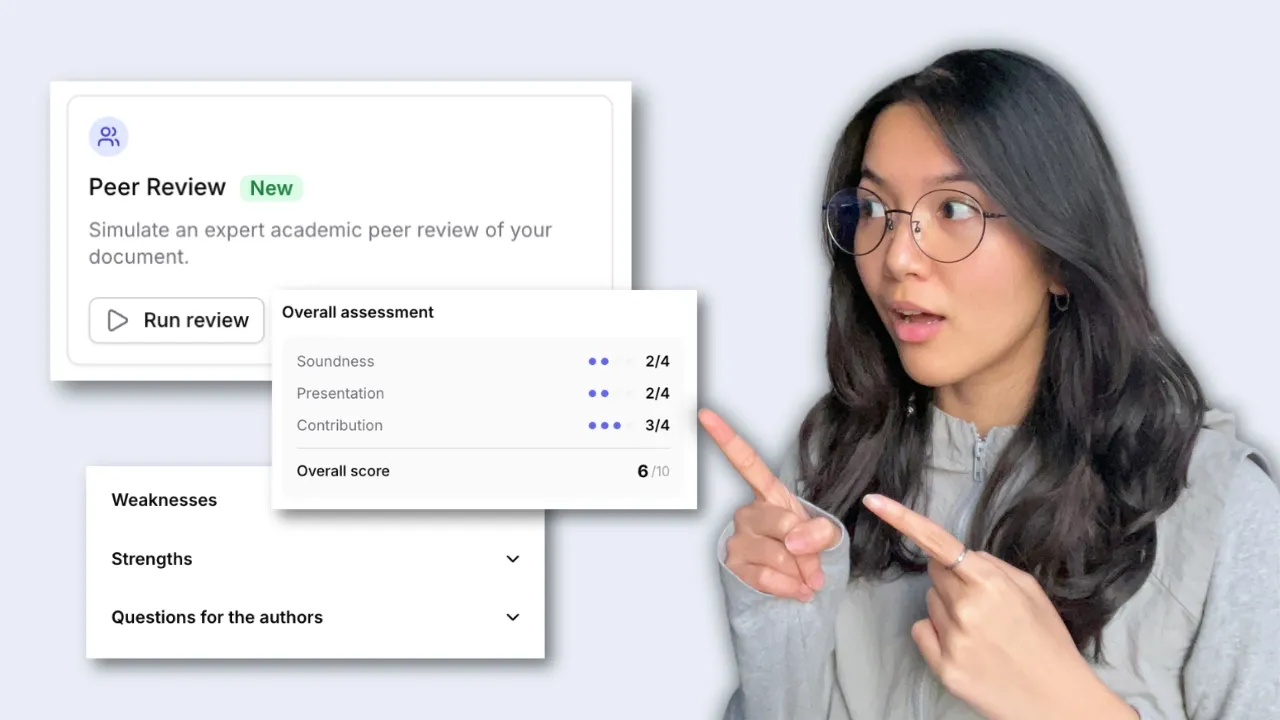
Peer Review, en iyi dergilerin kullandığı aynı hakem değerlendirme formunu doldurur; sağlamlık, katkı ve sunum için puanlar verir ve ayrıca yazılı geri bildirim sağlar.

Metin parçalarına bağlı yorumlar
Jenni, her yorumu belirli bir cümleye bağlar; nedeni ve önerilen düzeltmeyi de sunar. Böylece yalnızca bir şeylerin yanlış olduğunu değil, tam olarak neyi nerede değiştirmeniz gerektiğini de bilirsiniz.
Gönderim öncesi kapsamlı atıf incelemeniz
Akademik Hakem Değerlendirmesi, çalışmanız hakemlerin karşısına çıkmadan önce hataları yakalayan dört güçlü kontrol aracımızdan biridir. Yazınızı teslim etmeden önce eksiksiz bir ön kontrolden geçirmek için tüm araçları birlikte çalıştırın.
Peer review8 / 10
Manuscript scored against a peer-review rubric with reviewer comments on each section.
Soundness
3/4
Presentation
4/4
Contribution
3/4
Results
Strengths
Weaknesses
Claim confidence10 issues
The claim confidence analysis addressed issues of redundant, weak, or missing citations, alongside instances of contradiction in citation arguments.
Misrepresented
Contradicted
3Unsupported
4Weakly supported
2Overstated
Unverifiable
Outdated
2Self-citation heavy
Predatory source
Citation mismatch
1Proofread18 edits
Whilst generally sound, the text contains some areas for improvement to comply with academic best practices.
Word choice
AllThe majority of participants reported improved outcomes.
Formality
Yang (2024) found a negative correlation which was interesting..
Grammar
These results indicate that early intervention be effective. appears to be effective.
Transitions
Also, In addition, Jones (2022) found similar results.
Overgeneralized
AllThe majority of participants reported improved outcomes.
The results provesuggest that X has an effect on Y.Tone of voice22 notes
Suggestions across vocabulary, syntax, punctuation, tone and flow to keep a consistent academic voice.
All Suggestions
22Vocabulary
6Syntax
5Punctuation
4Tone
3Flow
4Akran Değerlendirmesi
Güvenle Yola Çıkın
Düzenleme ve Kontrol
Ses Tonu


Kullanıcılarımız 100'den fazla dergide makale yayımladı
IEEE, Springer ve Elsevier gibi dergilerde yayımlanan gerçek araştırmalar — Jenni ile planlandı ve yazıldı.
